AI Comparison Tools: Compare ChatGPT, Claude, Gemini, and 5 More AI Models
Compare AI Tools
Expert side-by-side analysis, benchmarking, and feature comparisons for the world’s most powerful AI models.
Tool Selection
Choose the models you want to analyze
Analyzing technical specifications and performance data…
AI comparison tools are platforms that benchmark and rank large language models. These platforms evaluate ChatGPT (OpenAI), Claude (Anthropic), Gemini (Google DeepMind), Grok (xAI), DeepSeek (High-Flyer Capital), and Perplexity AI using standardized performance metrics. Metrics include accuracy, speed, context window size, pricing, and integration capability.
This guide evaluates 7 major AI models across 5 measurable criteria. Benchmark data comes from LMSYS Chatbot Arena, MMLU, HumanEval, and SWE-bench Verified. It covers a 3-step selection framework for developers, content creators, and researchers selecting the correct AI tool in 2026.
What Are AI Comparison Tools?
AI comparison tools are user-facing platforms that evaluate, benchmark, and rank AI models like ChatGPT, Claude, and Gemini. They measure performance across accuracy, response speed, context window size, pricing, and integration capability. Platforms like Artificial Analysis, ChatHub, Poe, and ai comparison function as the primary evaluation layer between AI model developers and end users selecting the correct model for their workflow.
AI comparison tools eliminate the fragmentation problem in the 2026 AI market. Every provider OpenAI, Anthropic, Google DeepMind, xAI, and High-Flyer Capital maintains a separate platform with distinct pricing and benchmarks. AI comparison tools consolidate performance data into a single interface. This reduces the cost of model selection for developers, content creators, and enterprise teams.
How Do AI Comparison Tools Evaluate AI Models?
AI comparison tools assess models across 5 standardized criteria. Identical prompt sets run on standardized hardware measure performance delta across models. The 5 evaluation criteria applied by AI comparison tools include:
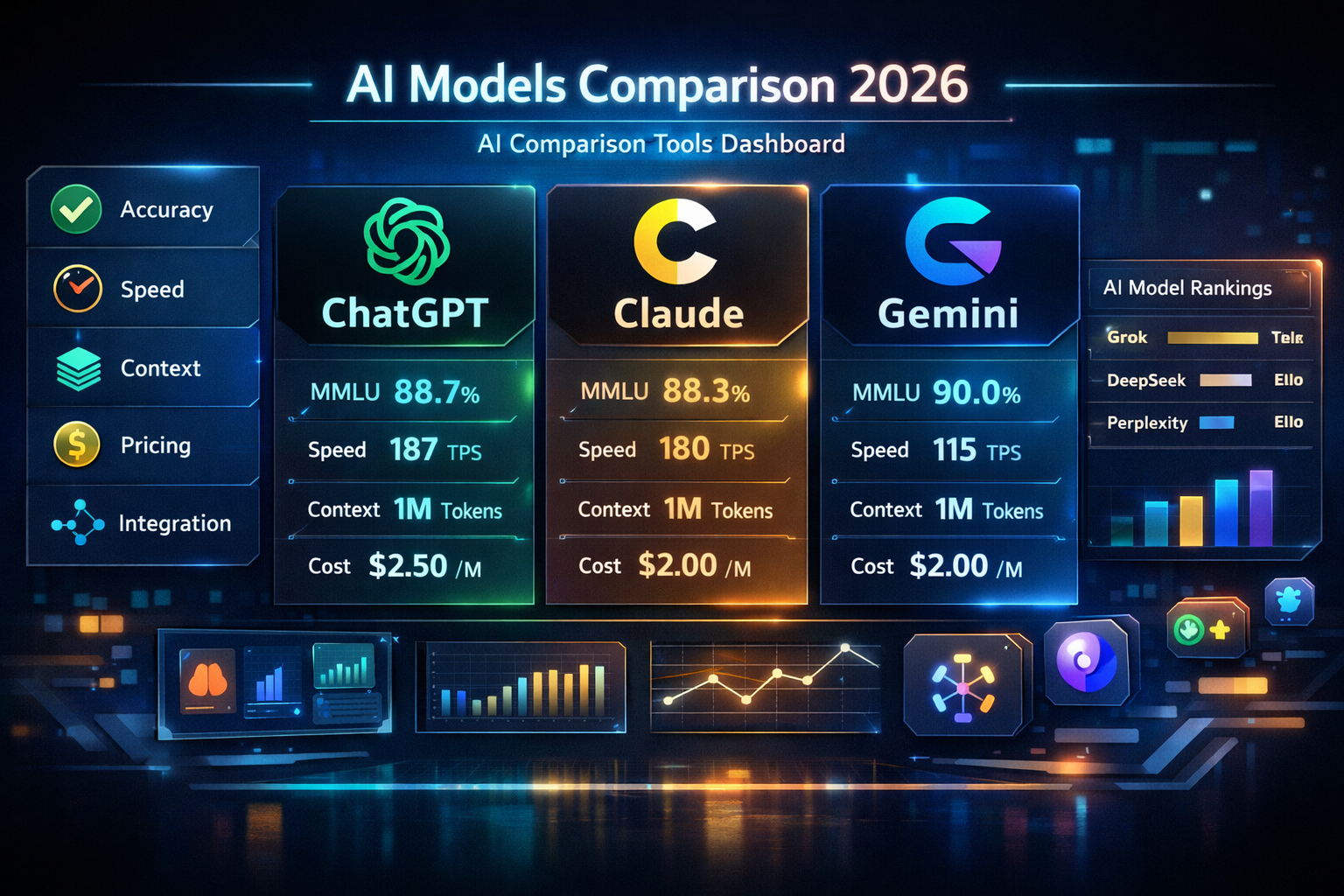
- Accuracy measured via MMLU benchmark across 57 academic subjects. Gemini 3.1 Pro scores 90.0%, GPT-5.4 scores 88.7%, and Claude 4.6 scores 88.3%. GPQA Diamond measures doctoral-level reasoning accuracy.
- Response speed measured via tokens per second (TPS). Grok 4.20 leads at 194 TPS. GPT-5.4 nano follows at 187 TPS. Gemini 3.1 Pro records 115 TPS, according to Artificial Analysis live benchmarks, April 2026.
- Context window measured via tokens. Grok 4.20 leads at 2,000,000 tokens. Gemini 3.1 Pro and Claude 4.6 Max reach 1,000,000 tokens. GPT-5.4 supports 1,050,000 tokens.
- Pricing measured via cost per 1 million input tokens. DeepSeek V3.2 leads at $0.28. Grok 4.1 Fast costs $0.20. Gemini 3.1 Pro costs $2.00. GPT-5.4 costs $2.50.
- Integration capability measured via BFCL v4 tool-use benchmark scores for multi-turn agentic workflow accuracy.
AI Comparison Tools vs AI Benchmarking Platforms: 3 Key Differences
AI comparison tools provide interactive, user-facing prompt testing interfaces. AI benchmarking platforms like Artificial Analysis and LMSYS Chatbot Arena hosted on Hugging Face deliver automated technical scores from standardized evaluations.
| Aspect | AI Comparison Tools | AI Benchmarking Platforms |
| Target Audience | End users, content creators, product managers | AI researchers, developers, model architects |
| Primary Output | Live side-by-side chat interfaces | Static leaderboards and Elo ratings |
| Core Methodology | Practical prompt testing | Standardized academic tests MMLU, GPQA Diamond |
The first difference is user interaction. Comparison tools like Poe and ChatHub allow live prompt testing across ChatGPT, Claude, Gemini, and Grok simultaneously. LMSYS Chatbot Arena aggregates thousands of blind pairwise votes to generate statistical Elo rankings.
The second difference is data scope. Comparison tools measure task utility for specific use cases like coding or writing. Benchmarking platforms measure frontier performance on doctoral-level academic tests including GPQA Diamond and AIME 2025.
The third difference is update frequency. Comparison tools update interfaces immediately upon model release. Benchmarking platforms require weeks of rigorous testing to prevent score contamination from training data memorization.
5 Criteria for Comparing AI Models Across Any Use Case
The 5 universal criteria accuracy, context window, response speed, pricing, and integration capability apply equally to ChatGPT, Claude, Gemini, Grok, and DeepSeek across any professional use case in 2026.
1. AI Model Accuracy: How Correctly Does Each Model Respond?
Accuracy measures the correctness of AI model outputs across factual, reasoning, and coding tasks. Standardized benchmarks including MMLU, GPQA Diamond, and HumanEval provide the measurement framework. In 2026, general knowledge benchmarks like MMLU have reached saturation among flagship models. Scores range between 87.5% and 90.0%. Harder tests including MMLU-Pro and GPQA Diamond now differentiate top-tier models on doctoral-level scientific reasoning.
| Model | MMLU (%) | GPQA Diamond (%) | HumanEval (%) | SWE-bench (%) |
| Gemini 3.1 Pro | 90.0 | 94.3 | 84.1 | 63.8 |
| GPT-5.4 | 88.7 | 92.0 | 90.2 | 75.0 |
| Claude Opus 4.6 | 88.3 | 91.3 | 92.0 | 80.8 |
| DeepSeek V3.2 | 88.5 | 82.0 | 89.0 | 60.0 |
| Grok 4.20 | 87.5 | N/A | 88.0 | 55.0 |
Claude Opus 4.6 and Grok 4.20 Beta feature Extended Thinking mode. This reasoning toggle allows each model to self-correct before delivering a final response. According to xAI’s Grok 3 Beta benchmark release, March 2025, Grok 3 in Think mode achieved 93.3% accuracy on AIME 2025. Extended reasoning directly increases output accuracy on complex logic and math tasks.
2. Context Window Size: How Much Data Does Each AI Model Process at Once?
Context window size defines the maximum volume of data an AI model processes in a single interaction. It is measured in tokens, where 1,000 tokens equals approximately 750 words. In 2026, the baseline context window for flagship models has moved from 128,000 tokens to 1,000,000 tokens or more. This enables full document analysis, codebase review, and long-form research synthesis within a single prompt.
| Model | Context Window | Practical Capacity |
| Grok 4.20 | 2,000,000 tokens | ~3,000 pages of text |
| GPT-5.4 | 1,050,000 tokens | ~1,600 pages of text |
| Gemini 3.1 Pro | 1,000,000 tokens | ~1,500 pages or 1 hour of video |
| Claude 4.6 Max | 1,000,000 tokens | ~1,500 pages of text |
| DeepSeek V3.2 | 164,000 tokens | ~125 pages of text |
Gemini 3.1 Pro’s 1,000,000 token context window enables processing of an entire 45-minute video with audio, according to Google Cloud Vertex AI video understanding documentation. It answers specific temporal questions within that video. DeepSeek V3.2, capped at 164,000 tokens, does not support this capability. Larger context windows directly improve performance on legal document review, full codebase analysis, and multi-source research synthesis.
3. AI Response Speed and Latency: How Fast Does Each Model Generate Output?
Response performance measures two distinct variables throughput in tokens per second and latency as time to first token (TTFT). Throughput determines sustained generation speed. TTFT determines perceived responsiveness for interactive applications. Models operating in Extended Thinking mode show significantly higher TTFT values. They trade initial latency for improved output accuracy, according to Artificial Analysis live benchmark data, April 2026.
| Model | Output Speed (TPS) | Latency TTFT (seconds) |
| Grok 4.20 | 194 tokens/sec | 11.08s |
| GPT-5.4 nano | 187 tokens/sec | 4.32s |
| Gemini 3.1 Pro | 115 tokens/sec | 33.27s (reasoning mode) |
| Claude Opus 4.6 | 47 tokens/sec | 19.31s (max thinking) |
Grok 4.20 leads at 194 tokens per second the fastest major model for real-time intelligence feeds and customer service automation. GPT-5.4 nano delivers the lowest latency at 4.32 seconds TTFT. This makes it the most responsive model for interactive conversational applications where perceived speed matters more than raw output volume.
4. AI Pricing Models: What Does Each AI Tool Cost Per Month or Per Token?
AI tool pricing in 2026 operates across 3 distinct tiers consumer subscriptions at $20/month, high-end plans at $100–$200/month, and developer API pricing per 1 million tokens. The correct tier depends on usage volume, reasoning intensity, and deployment context. Prompt caching reduces repeated long-context API costs by up to 90% across OpenAI, Anthropic, and Google APIs, according to their respective pricing pages, April 2026.
| Service | Monthly Cost | Primary Model | Key Feature |
| ChatGPT Plus | $20.00 | GPT-5.4 | DALL-E 4 + 25 Deep Research uses/month |
| Claude Pro | $20.00 | Claude 4.6 | 5x usage limits + Claude Cowork tools |
| Google AI Pro | $19.99 | Gemini 3.1 Pro | 2TB Google Cloud storage + YouTube Premium |
| Perplexity Pro | $20.00 | GPT-5.4 / Claude 4.6 | 300+ Pro searches/day + model selection |
| Grok Premium | $30.00 | Grok 4.20 | X Premium+ + real-time social data access |
Developer API costs per 1 million input tokens across 5 providers:
| Provider | Model | Input $/1M | Output $/1M | Caching |
| xAI | Grok 4.1 Fast | $0.20 | $0.50 | Competitive |
| DeepSeek | V3.2 | $0.28 | $0.42 | N/A |
| Gemini 3.1 Pro | $2.00 | $12.00 | Excellent | |
| OpenAI | GPT-5.4 | $2.50 | $10.00 | Up to 90% |
| Anthropic | Claude 4.6 | $5.00 | $25.00 | Strong |
DeepSeek V3.2 at $0.28 per million input tokens delivers MMLU-level accuracy. Its cost is approximately 9x lower than GPT-5.4 and approximately 18x lower than Claude 4.6. The Intelligence-per-Dollar ratio positions DeepSeek V3.2 and Grok 4.1 Fast as the highest-value API options for budget-conscious developers in 2026.
5. AI Integration Capability: Which AI Tools Connect With External Platforms?
Integration capability defines an AI model’s utility within broader technical ecosystems. It is evaluated via native platform connections, API compatibility, and BFCL v4 tool-use benchmark scores for multi-turn agentic workflow accuracy.
ChatGPT GPT-5.4 connects natively with Zapier, Slack, Microsoft Teams, and HubSpot. It supports thousands of automation workflows for non-technical teams through a single interface.
Claude 4.6 specializes in developer ecosystem integration. It connects with Amazon Bedrock, Google Cloud, and GitHub via the Claude Code CLI tool. This allows direct code commits and test execution without leaving the terminal.
Gemini 3.1 Pro delivers the deepest productivity integration. It connects natively with Gmail, Google Docs, Google Sheets, Google Slides, and Google Drive. Tasks like summarizing a month of emails or formatting a slide deck from a raw spreadsheet execute directly within the Google Workspace interface.
AI Model Benchmark Comparison: ChatGPT, Claude, Gemini, Grok, and DeepSeek Scores
The 3 primary benchmarks for evaluating AI models in 2026 are LMSYS Chatbot Arena, MMLU, and HumanEval. LMSYS Chatbot Arena, hosted on Hugging Face, uses blind pairwise human preference voting to generate Elo ratings. MMLU tests academic knowledge across 57 subjects. HumanEval measures Python code generation accuracy on 164 programming tasks.
| Model | MMLU (%) | LMSYS Elo | HumanEval (%) | GPQA (%) | SWE-bench (%) | Context |
| Claude Opus 4.6 | 88.3 | 1504 (#1) | 92.0 | 91.3 | 80.8 | 1M |
| Gemini 3.1 Pro | 90.0 | 1494 (#2) | 84.1 | 94.3 | 63.8 | 1M |
| Grok 4.20 | 87.5 | 1491 (#3) | 88.0 | N/A | 55.0 | 2M |
| GPT-5.4 | 88.7 | 1484 (#4) | 90.2 | 92.0 | 75.0 | 1.1M |
| DeepSeek V3.2 | 88.5 | 1425 (#5) | 89.0 | 82.0 | 60.0 | 164K |
How Does ChatGPT GPT-5.4 Score on MMLU and LMSYS Arena Benchmarks?
ChatGPT GPT-5.4 scores 88.7% on MMLU, 90.2% on HumanEval, and holds the #4 position on LMSYS Chatbot Arena with an Elo rating of 1484. It delivers balanced performance across academic knowledge, coding, and conversational tasks. GPT-5.4 supports text, image generation via DALL-E 4, voice, code, and real-time web search through Browse with Bing. OpenAI, founded in 2015, serves 180 million weekly active users with GPT-5.4, according to OpenAI’s 2024 usage data the largest active user base among current AI models.
GPT-5.4’s “High” variant scores 75% on the OSWorld benchmark for computer interaction tasks. Claude Opus 4.6 scores 80.8% on SWE-bench Verified against GPT-5.4’s 75.0% on OSWorld a full benchmark breakdown is available in the Claude vs ChatGPT comparison.
How Does Claude 4.6 Score on Reasoning and Coding Benchmarks?
Claude Opus 4.6 holds the #1 position on LMSYS Chatbot Arena at 1504 Elo, scores 91.3% on GPQA Diamond, and achieves 80.8% on SWE-bench Verified the highest SWE-bench score ever recorded for an AI model, according to Anthropic’s Claude 4.6 technical report, 2026. Anthropic, founded in 2021, developed Constitutional AI as its primary safety framework. This gives Claude 4.6 a measurable advantage in tone control and enterprise-safe output generation.
Claude 4.6 in Extended Thinking mode scores 91.3% on GPQA Diamond the highest reasoning accuracy among current flagship models, according to LMSYS Chatbot Arena data. Claude 4.6 scores 80.8% on SWE-bench against Gemini 3.1 Pro’s 63.8% a full benchmark breakdown is available in the Claude vs Gemini comparison.
How Does Gemini 3.1 Pro Score on Multimodal and Language Benchmarks?
Gemini 3.1 Pro scores 90.0% on MMLU, 94.3% on GPQA Diamond the highest scientific reasoning score among all current flagship models and holds the #2 position on LMSYS Chatbot Arena at 1494 Elo, according to Google DeepMind’s Gemini 3.1 Pro technical report. Google DeepMind, formed through the merger of Google Brain and DeepMind in 2023, developed Gemini 3.1 Pro with 6 native input modalities text, image, audio, video, code, and documents within a single 1,000,000 token context window.
Gemini 3.1 Pro scores 92.6% on the MMMLU multilingual benchmark, according to Google DeepMind’s Gemini 3.1 Pro technical report. This makes it the strongest model for international enterprise deployments requiring non-English language accuracy. Gemini 3.1 Pro scores 90.0% on MMLU against GPT-5.4’s 88.7% a full evaluation is available in the Gemini vs ChatGPT comparison.
How Does Grok 4.20 Score on HumanEval Coding Benchmarks Against GPT-5.4?
Grok 4.20 scores 88.0% on HumanEval against GPT-5.4’s 90.2%, delivering competitive coding performance at the highest output speed of any current flagship model at 194 tokens per second. Developed by xAI, founded by Elon Musk, and trained on the Colossus supercluster, Grok 4.20 holds the #3 position on LMSYS Chatbot Arena at 1491 Elo rising 59 Elo points above DeepSeek V3.2 at 1425.
Grok 4.20’s primary differentiator is real-time data access from the X (Twitter) platform. This enables current event analysis, cultural trend tracking, and social data synthesis that static knowledge models cannot perform. In Think mode, Grok 3 achieved 93.3% accuracy on AIME 2025, according to xAI’s Grok 3 Beta benchmark release, March 2025. Grok 4.20 scores 88.0% HumanEval against GPT-5.4’s 90.2% a full speed and reasoning breakdown is available in the Grok vs ChatGPT comparison.
How Does DeepSeek V3.2 Score on Cost-Per-Token and MMLU Benchmarks?
DeepSeek V3.2 costs $0.28 per million input tokens approximately 9x cheaper than GPT-5.4 at $2.50 and approximately 18x cheaper than Claude 4.6 at $5.00 while scoring 88.5% on MMLU, within 0.2 percentage points of GPT-5.4’s 88.7%. Developed by High-Flyer Capital in China, DeepSeek V3.2 uses a Mixture-of-Experts architecture. It activates only 37 billion of 671 billion total parameters per token.
DeepSeek V3.2 holds the #5 position on LMSYS Chatbot Arena at 1425 Elo within 59 Elo points of GPT-5.4 at 1484. It operates as an open-weight model. Developers download, self-host, and deploy it on private infrastructure without third-party API dependency. DeepSeek V3.2 scores 88.5% MMLU at $0.28/1M tokens against GPT-5.4’s $2.50/1M a full cost-performance breakdown is available in the DeepSeek vs ChatGPT comparison.
AI Tool Pricing Comparison: Free, Paid, and API Plans for 7 Major AI Models
AI tool pricing in 2026 operates across 3 tiers free consumer plans with usage caps including message limits, model version caps, and feature lockouts; standard subscriptions at $19.99–$30/month; and developer API plans priced per 1 million tokens. All 7 major AI models offer a free entry point with varying capability restrictions. Prompt caching across OpenAI, Anthropic, and Google APIs reduces repeated long-context costs by up to 90%, according to their respective pricing pages, April 2026.
What AI Tools Offer a Free Plan With No Usage Limits?
No flagship AI model offers unlimited free access to its most capable version. Free plans across ChatGPT, Claude, Gemini, Perplexity, and Grok provide reduced model access with daily usage caps including message limits, model version caps, and feature lockouts. Each free plan follows this structure: Platform → Free Model → Daily Limit → Primary Capability → Restriction.
Gemini (Google DeepMind): Free tier provides Gemini 3 Flash access. Daily limit is 30 prompts. Primary capability is native Google Search grounding enabled by default. Restriction is no Gemini 3.1 Pro access, according to Google’s AI subscription limits page.
ChatGPT (OpenAI): Free version uses GPT-5 mini. Daily limit is essentially unlimited for text generation. Primary capability is general conversational tasks. Restriction is strictly capped document analysis, DALL-E 4 image generation, and extended reasoning, according to OpenAI’s pricing page.
Perplexity AI: Free version provides unlimited standard web searches. Daily limit is unlimited for standard queries. Primary capability is real-time source citations on every response. Restriction is 5 Pro searches per day without a paid subscription, according to Perplexity AI’s product page.
Claude (Anthropic): Free plan provides Claude 4.6 limited access. Daily limit is approximately one-fifth of Claude Pro message volume. Primary capability is occasional document analysis and writing tasks. Restriction is dynamic usage limits that shift based on server demand, according to Anthropic’s pricing page.
Grok (xAI): Free tier provides basic Grok model access through the X platform. Daily limit is restricted queries without specific published count. Primary capability is basic conversational tasks. Restriction is no real-time X data integration or Extended Thinking mode both require the $30/month Grok Premium subscription.
What Is the Monthly Cost of ChatGPT Plus, Claude Pro, and Gemini Advanced?
The standard consumer subscription price across ChatGPT Plus, Claude Pro, and Perplexity Pro is $20/month. Google AI Pro costs $19.99/month. Grok Premium costs $30/month the highest consumer subscription price among major AI services in 2026.
| Service | Monthly Cost | Primary Model | Key Feature |
| ChatGPT Plus | $20.00 | GPT-5.4 | DALL-E 4 + 25 Deep Research uses/month |
| Claude Pro | $20.00 | Claude 4.6 | 5x usage limits + Claude Cowork tools |
| Google AI Pro | $19.99 | Gemini 3.1 Pro | 2TB storage + YouTube Premium |
| Perplexity Pro | $20.00 | GPT-5.4 / Claude 4.6 | 300+ Pro searches/day + model selection |
| Grok Premium | $30.00 | Grok 4.20 | X Premium+ + real-time social data |
Perplexity Pro at $20/month provides access to both GPT-5.4 and Claude 4.6 as selectable models. It bundles real-time search, GPT-5.4 reasoning, and Claude 4.6 prose into a single subscription. Google AI Pro at $19.99/month bundles Gemini 3.1 Pro with 2TB Google Cloud storage and YouTube Premium.
Claude Max and ChatGPT Pro operate above the standard $20/month tier at $100–$200/month. These plans provide unlimited reasoning access and 20x higher usage limits for enterprise teams and high-volume professional users.
What Does the OpenAI API Cost Compared to Anthropic and Google AI APIs?

OpenAI GPT-5.4 API costs $2.50 per million input tokens and $10.00 per million output tokens. Anthropic Claude 4.6 costs $5.00 input and $25.00 output. Google Gemini 3.1 Pro costs $2.00 input and $12.00 output. DeepSeek V3.2 costs $0.28 input and $0.42 output. xAI Grok 4.1 Fast costs $0.20 input and $0.50 output.
| Provider | Model | Input $/1M | Output $/1M | Caching |
| xAI | Grok 4.1 Fast | $0.20 | $0.50 | Competitive |
| DeepSeek | V3.2 | $0.28 | $0.42 | N/A |
| Gemini 3.1 Pro | $2.00 | $12.00 | Excellent | |
| OpenAI | GPT-5.4 | $2.50 | $10.00 | Up to 90% |
| Anthropic | Claude 4.6 | $5.00 | $25.00 | Strong |
Anthropic Claude 4.6 carries the highest API cost at $5.00 per million input tokens. This is 2x GPT-5.4 and approximately 18x DeepSeek V3.2. It is justified by Claude 4.6’s #1 LMSYS Arena ranking at 1504 Elo and 80.8% SWE-bench score. OpenAI’s prompt caching discount of up to 90% makes GPT-5.4 the most cost-efficient US-based option for long-context repeated prompt applications. For a full breakdown of lower-cost model alternatives, the ChatGPT alternatives guide covers 8 models with full pricing and benchmark comparisons.
Best AI Tool Across 4 Use Cases: Writing, Coding, Research, and Automation
Claude 4.6 leads content writing. Claude Code leads software engineering. Perplexity AI leads research. n8n leads AI-native workflow automation. Each model delivers measurably superior performance within its primary use case based on benchmark scores, acceptance rates, and architectural capabilities in 2026.
Which AI Tool Scores Highest for Content Writing: Claude, ChatGPT, or Jasper AI?
Claude 4.6 scores highest for content writing due to superior tone control, narrative consistency across 1,000,000 token contexts, and Constitutional AI safety guardrails. According to Zemith’s 2026 AI writing tool evaluation scoring prose naturalness across 12 tested tools, Claude 4.6 scores highest on prose quality, stylistic consistency, and instruction-following accuracy among current AI writing tools.
Claude 4.6 (Anthropic): Delivers the highest prose quality among current flagship models. Its 1,000,000 token context window enables full-length book editing, long-form research reports, and multi-chapter document analysis within a single session.
ChatGPT GPT-5.4 (OpenAI): Delivers the strongest performance for versatile short and medium-form content. This includes social media copy, product descriptions, and email campaigns. GPT-5.4’s DALL-E 4 integration adds native image generation within the same writing workflow.
Jasper AI: Operates at $59/month with marketing-specific workflow wrappers for SEO content briefs and brand voice templates. Claude Pro scores higher on prose quality benchmarks at one-third of Jasper AI’s $59/month cost making it the correct choice for content creators requiring individual writing quality over marketing pipeline features. Jasper AI’s $59/month cost against ChatGPT’s $20/month a full feature and pricing breakdown is available in the Jasper AI vs ChatGPT comparison.
Which AI Coding Assistant Performs Best: GitHub Copilot, Claude Code, or Cursor?
Claude Code scores highest on SWE-bench Verified at 80.8% the highest score ever recorded for an AI model resolving real-world GitHub issues, according to Anthropic’s Claude 4.6 technical report, 2026. This makes it the strongest coding assistant for complex architectural refactoring, autonomous bug fixing, and multi-file codebase changes.
| Tool | Format | Performance Metric | Best For |
| Claude Code | Terminal Agent | 80.8% SWE-bench Verified | Complex refactoring and autonomous bug fixing |
| Cursor | AI-Native IDE | 72% Supermaven acceptance rate | Daily development and multi-file editing |
| GitHub Copilot | IDE Extension | 46% code acceptance rate | Enterprise autocomplete |
Claude Code (Anthropic): Operates as a terminal-based agentic coding tool. It runs tests, commits code directly to GitHub, and executes autonomous debugging loops without manual intervention between steps.
Cursor: Functions as an AI-native IDE built on Claude 4.6 or GPT-5.4. Supermaven autocomplete delivers a 72% code acceptance rate, according to Cursor’s 2026 product documentation. This is significantly higher than GitHub Copilot’s 46%, according to GitHub’s Developer Survey 2023. Cursor’s “Composer” feature enables multi-file editing across an entire project directory.
GitHub Copilot (Microsoft): Operates as an IDE extension across Visual Studio Code, JetBrains, and Neovim. It records a 46% code acceptance rate across more than 1 million active developers, according to GitHub’s Developer Survey 2023. Claude Code scores 80.8% on SWE-bench against Cursor’s 72% Supermaven acceptance rate a full breakdown is available in the Claude Code vs Cursor comparison.
Which AI Tool Is Best for Research: Perplexity AI, Gemini, or ChatGPT?
Perplexity AI scores highest for research tasks due to its source-first RAG architecture that performs a fresh real-time web crawl on every query. It delivers inline citations on every response. This eliminates the hallucination risk common in non-grounded models including base Claude 4.6 and DeepSeek V3.2.
Perplexity AI: Performs real-time RAG web crawls on every query. It delivers verifiable inline citations linking directly to primary sources. Perplexity AI processes 10 million queries per day making it the dominant AI research tool among journalists, analysts, and fact-checkers, according to Perplexity AI’s 2024 usage data.
Gemini 3.1 Pro (Google DeepMind): Uses native Google Search grounding to synthesize current news, technical documentation, and academic sources. Its 1,000,000 token context window enables research synthesis across YouTube video transcripts, academic PDFs, and live news articles simultaneously.
ChatGPT GPT-5.4 (OpenAI): Features a Deep Research agent that autonomously navigates the web across multiple sources. It performs best on open-ended investigative tasks requiring multi-hop reasoning across dozens of web sources. Perplexity AI’s real-time RAG architecture against ChatGPT’s Deep Research agent a full research performance comparison is available in the Perplexity vs ChatGPT comparison.
Which AI Tool Leads Workflow Automation: ChatGPT, Claude, or n8n?
n8n leads AI-native workflow automation in 2026. It uses first-class LLM agent architecture, native LangChain integration, and self-hostable infrastructure. n8n treats AI agents as core workflow primitives rather than add-on features.
n8n: Operates as an open-source, self-hostable workflow automation platform with 40,000+ GitHub stars. It integrates natively with LangChain, enabling AI agent loops where the model executes a task, checks for errors, and self-corrects without human intervention. n8n enables on-premise deployment keeping all workflow data within the organization’s own infrastructure without third-party API transmission.
ChatGPT via Zapier (OpenAI + Zapier): Supports 7,000+ application integrations through Zapier’s connector library. It enables non-technical teams to build marketing operations, CRM updates, and content publishing workflows without writing code.
Claude Computer Use (Anthropic): Enables cursor-level desktop automation. Claude 4.6 directly controls mouse clicks, keyboard inputs, and screen navigation extending automation to legacy software systems including SAP, older CRM platforms, and desktop-only enterprise tools that Zapier and n8n cannot reach through standard API connectors. n8n’s LangChain agent loops against Zapier’s 7,000+ trigger-based connectors a full automation comparison is available in the n8n vs Zapier comparison.
2 AI Categories Explained: Grounded vs Non-Grounded Models for AI Comparison
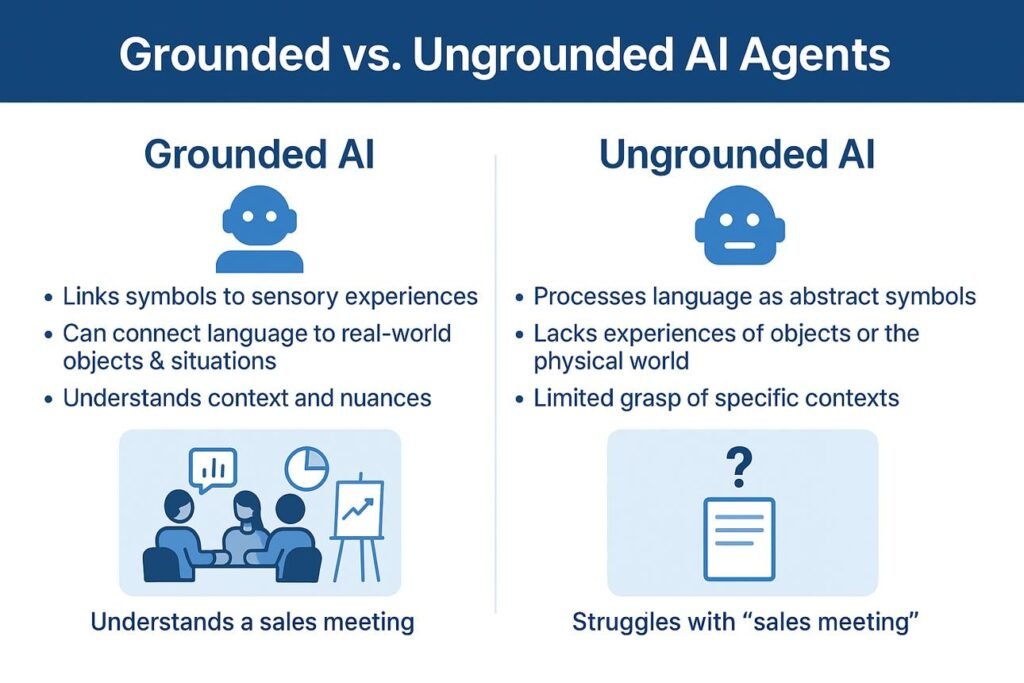
Understanding grounded and non-grounded AI categories directly improves AI comparison tool selection accuracy. The 2 categories grounded models with real-time web access and non-grounded models with static training data determine which comparison criteria apply to each model. This distinction affects output accuracy, hallucination rate, and suitability for time-sensitive research tasks.
What Is Grounded AI and Which Models Use Real-Time Web Access?
Grounded AI refers to models that use RAG or native search integration to retrieve live web data before generating a response. Retrieved source documents ground every output in verifiable information. Grounded AI models produce lower hallucination rates than non-grounded models on current events and time-sensitive factual queries reducing hallucination rates on current event queries, according to Perplexity AI’s internal accuracy benchmarks.
The 3 primary grounded AI models in 2026 use distinct retrieval architectures:
Perplexity AI: Performs a fresh real-time web crawl on every single query using RAG methodology. It delivers inline citations alongside every factual claim. Perplexity AI processes 10 million queries per day making it the dominant grounded AI tool for research and fact-checking workflows, according to Perplexity AI’s 2024 usage data.
Gemini 3.1 Pro (Google DeepMind): Uses native Google Search integration to ground responses in current web data. It leverages Google’s search index covering more than 100 billion web pages. Its grounding extends across multimodal inputs including video, audio, and PDF documents alongside live web search results.
ChatGPT GPT-5.4 (OpenAI): Uses Browse with Bing integration for real-time web access. Its Deep Research agent autonomously navigates multiple web sources. It covers research tasks combining YouTube video transcripts, academic PDFs, and live news articles. Perplexity AI’s RAG retrieval against Gemini 3.1 Pro’s Google Search grounding a full retrieval methodology comparison is available in the Perplexity vs Gemini comparison.
What Is Non-Grounded AI and When Does Static Knowledge Perform Better?
Non-grounded AI refers to models that generate responses exclusively from static pre-trained internal weights without retrieving external data. These models operate with a fixed knowledge cutoff date covering events, pricing changes, and product releases only up to that date. Non-grounded AI delivers superior performance on tasks where real-time retrieval introduces unnecessary latency including creative writing, code generation, document summarization, and mathematical reasoning.
| Model | Knowledge Cutoff | Optimized For |
| Claude 4.6 | May 2025 | Creative writing and narrative prose |
| GPT-5.3 Codex | October 2025 | High-logic coding and legacy systems |
| Gemini 3.1 | January 2025 | Scientific and academic reasoning |
| DeepSeek V3.2 | July 2024 | High-volume API calls and data classification |
Non-grounded models produce lower latency than grounded models. They eliminate web crawl wait time entirely. Non-grounded models generate creative writing without factual anchoring constraints from retrieved web documents. They produce higher stylistic consistency across long-form outputs.
Non-grounded models including Claude 4.6 at 80.8% SWE-bench and GPT-5.4 at 75.0% OSWorld deliver higher coding benchmark scores than grounded models. Code generation accuracy depends on pattern recognition within training data not real-time web retrieval. These advantages apply directly to comparison criteria 1 and 3 accuracy and response speed where static knowledge models outperform grounded models on Extended Thinking benchmarks.
Non-grounded models in Extended Thinking mode deliver higher mathematical accuracy. Claude Opus 4.6 Thinking holds 1504 LMSYS Elo. Grok 3 Think achieves 93.3% on AIME 2025. Mathematical problem-solving requires deep internal chain-of-thought reasoning rather than external source retrieval. Perplexity AI’s grounded research architecture against Claude’s non-grounded document analysis a full task-by-task breakdown is available in the Perplexity vs Claude comparison.
3 AI Platforms That Compare Multiple Models in One Interface
The 3 primary multi-model AI platforms Poe by Quora, ChatHub, and Artificial Analysis solve the subscription fragmentation problem in the 2026 AI market. They provide access to ChatGPT, Claude, Gemini, Grok, and DeepSeek through a single interface. This eliminates the need for separate subscriptions to each AI provider.
How Does Poe by Quora Enable Multi-Model AI Comparison?
Poe by Quora enables multi-model AI comparison by aggregating over 100 AI models from OpenAI, Anthropic, Google DeepMind, Meta, and Mistral into a single subscription interface. Poe eliminates separate API key management across 100+ models. Users switch between ChatGPT, Claude, Gemini, Llama, and Mistral within a single conversation thread.
Model coverage: Poe hosts over 100 AI models. These include GPT-5.4, Claude 3.7 Sonnet, Gemini 2.0, Llama 4, Mistral Large, and FLUX 1.1 image generation. This provides the broadest single-subscription model library among current multi-model platforms.
Multi-Bot Chat feature: Poe’s Multi-Bot Chat sends a single prompt to multiple AI models simultaneously. Responses appear side by side within one interface. This enables direct output quality comparison across ChatGPT, Claude, and Gemini on identical prompts without switching browser tabs.
Pricing: Poe Standard costs $19.99 per month. This provides 1 million compute points monthly. Premium models including GPT-5.4 and Claude Opus 4.6 consume more points per query than standard models.
Primary use case: Poe provides access to 100+ AI models through a single $19.99/month subscription covering GPT-5.4, Claude 4.6, and Gemini 3.1 Pro at a combined cost lower than 3 separate provider subscriptions totaling $60/month.
How Does ChatHub Enable Side-by-Side AI Model Testing?
ChatHub enables side-by-side AI model testing by allowing users to send a single prompt to up to 6 AI models simultaneously in a configurable grid layout. Direct parallel output comparison runs across ChatGPT, Claude, Gemini, Grok, and DeepSeek without requiring individual API keys for each provider.
Parallel testing architecture: ChatHub’s core function is A/B prompt testing. Users submit one prompt and receive responses from 2 to 6 models simultaneously. The side-by-side grid enables direct comparison of response quality, length, tone, and factual accuracy on identical inputs.
Model coverage: ChatHub accesses 20+ AI models including GPT-5, Claude 4.5, Gemini 3, Grok 4, and DeepSeek V3.2, according to ChatHub’s model library page, 2026. No individual subscriptions or API keys are required for each provider.
Pricing: ChatHub Pro costs $14.99 per month billed annually. The Unlimited plan costs $24.99 per month. This makes ChatHub the most cost-efficient dedicated multi-model testing platform among current options.
Primary use case: ChatHub delivers the strongest value for content creators, researchers, and product managers. It identifies which AI model produces the highest quality output for a specific repeated task such as writing product descriptions, summarizing documents, or generating code before committing to a single model subscription.
How Does Artificial Analysis Benchmark AI Models With Live Data?
Artificial Analysis, founded in 2023, provides the most objective AI model benchmarking data in 2026. It continuously tracks 188 AI models across 50+ providers on 5 standardized performance dimensions intelligence index, output speed, latency, price per million tokens, and context window size, according to Artificial Analysis leaderboard data, April 2026. It uses automated measurement rather than human editorial review.
Intelligence Index: Artificial Analysis computes a composite Intelligence Index score. It bases this on 10 independent evaluations spanning agentic task execution, coding accuracy, scientific reasoning, and language understanding. This provides a single normalized score enabling direct comparison across MoE and dense neural network architectures.
Live metric tracking: Artificial Analysis updates performance data continuously as new model versions release. It tracks output speed in tokens per second, time to first token in seconds, and price per million tokens across all 188 tracked models.
Model coverage: Artificial Analysis covers proprietary models OpenAI GPT-5.4, Anthropic Claude 4.6, Google Gemini 3.1 Pro and open-weight models including Llama 4, Mistral Large, and DeepSeek V3.2. It provides automated measurement across 188 models from 50+ providers the only neutral comparison engine covering both proprietary and open-weight AI models equally.
Primary use case: Artificial Analysis delivers the strongest value for developers, AI researchers, and enterprise procurement teams. It provides objective, methodology-backed performance data to justify model selection decisions as opposed to editorial sites that rely on subjective human review scores.
3-Step Framework for Selecting the Correct AI Tool
The 3-step AI tool selection framework define use case, match budget to pricing tier, and test against specific task applies to all AI model decisions involving ChatGPT, Claude, Gemini, Grok, DeepSeek, and Perplexity AI. Use case definition precedes pricing evaluation in the correct selection sequence.
Step 1: Define Your Primary Use Case Before Comparing AI Models
Match the primary task to the model architecturally optimized for that task. This produces better results than selecting the highest-ranked model on general leaderboards like LMSYS Chatbot Arena or MMLU. It narrows model selection to the most task-relevant options before pricing evaluation begins.
| Primary Task | Recommended Model | Primary Reason |
| Prose and Creative Writing | Claude 4.6 | Superior tone control across 1M token context |
| Complex Software Engineering | Claude Code or Cursor | 80.8% SWE-bench Verified highest ever recorded |
| Deep Research and Fact-Checking | Perplexity AI | Real-time RAG web crawl with inline citations |
| Multimodal and Ecosystem Work | Gemini 3.1 Pro | Native video understanding + Google Workspace |
Use case mismatches produce measurable performance deficits. A developer using Perplexity AI for code generation loses Claude Code’s 80.8% SWE-bench accuracy. A researcher using base Claude 4.6 for current event analysis loses Perplexity AI’s real-time citation architecture.
For users without a single dominant use case, ChatGPT GPT-5.4 delivers the broadest capability coverage at $20/month. The ChatGPT alternatives guide covers 8 specialized models that outperform GPT-5.4 in specific task categories.
Step 2: Match Your Budget to the Correct AI Pricing Tier
3 distinct budget categories exist in 2026 free, consumer subscription, and developer API each with a clearly optimal AI tool based on the Intelligence-per-Dollar ratio. Budget matching determines the correct pricing tier before model selection begins.
Tier 1 Free (Casual and Student Use): Gemini 3 Flash delivers the strongest free-tier experience. It provides 30 prompts per day with native Google Search grounding. ChatGPT Free using GPT-5 mini provides essentially unlimited text generation. It is the strongest free option for general conversational tasks.
Tier 2 $20/month (Professional Individual Use): Claude Pro at $20/month delivers the highest output quality per dollar for writing and legal analysis. It is justified by Claude 4.6’s #1 LMSYS Arena ranking at 1504 Elo. ChatGPT Plus at $20/month delivers the strongest all-round subscription value. It combines GPT-5.4 text, DALL-E 4 images, voice, and Deep Research within one plan. Perplexity Pro at $20/month delivers the highest research value per dollar. It provides 300+ Pro searches per day with GPT-5.4 and Claude 4.6 as selectable models.
Tier 3 Developer API (High-Volume Deployment): DeepSeek V3.2 at $0.28 per million input tokens delivers the highest Intelligence-per-Dollar ratio. It scores 88.5% on MMLU at a cost approximately 9x lower than GPT-5.4. Grok 4.1 Fast at $0.20 per million input tokens delivers the lowest API cost among major providers. It is the correct choice for maximum-volume deployments where cost minimization outweighs benchmark performance differences between models.
Step 3: Test the AI Model Against Your Specific Task Before Committing
Test AI models before committing by submitting the exact production prompt to Claude 4.6, GPT-5.4, and Gemini 3.1 Pro simultaneously via ChatHub’s parallel testing grid. Evaluate factual accuracy, tone, and structural quality across all 3 responses. Direct task testing measures real-world output quality on exact production inputs not standardized academic scores.
Method 1 ChatHub Parallel Testing: Submit the exact prompt from the primary use case to 4 models simultaneously via ChatHub. Compare Claude 4.6, GPT-5.4, Gemini 3.1 Pro, and DeepSeek V3.2 outputs side by side. ChatHub Pro costs $14.99/month. Submit a 500-word document summary request to all 4 models. Evaluate factual accuracy, tone consistency, and structural organization across all 4 responses before selecting a primary model.
Method 2 Poe Multi-Model Conversation Switching: Use Poe’s Multi-Bot Chat to switch between Claude 4.6, GPT-5.4, and Gemini 3.1 Pro within a single conversation thread. Test how each model handles follow-up questions, context retention, and stylistic consistency across multi-turn interactions. Poe’s $19.99/month subscription provides access to 100+ models within a single interface.
Method 3 Consensus Rule Verification: Apply the Consensus Rule if Claude 4.6, GPT-5.4, and Gemini 3.1 Pro all produce the same factual answer to a specific query, factual confidence in that answer is high. If the 3 models produce conflicting answers, use Perplexity AI to retrieve the primary source. The Consensus Rule delivers the most reliable factual verification methodology for research tasks where hallucination risk is high.
Choose the Correct AI Model: ChatGPT, Claude, Gemini, Perplexity, or DeepSeek?
The correct AI model selection in 2026 depends entirely on the primary use case. ChatGPT leads versatile general-purpose tasks. Claude leads document analysis and software engineering. Gemini leads multimodal research and Google ecosystem work. Perplexity leads real-time web research. DeepSeek leads high-volume API deployments at minimum cost.
Choose ChatGPT for Versatile Writing, Coding, and Image Generation Tasks
Choose ChatGPT for versatile writing, coding, and image generation tasks. GPT-5.4’s broad multimodal capability across text, image, voice, code, and real-time web search delivers the strongest all-round performance within a single $20/month subscription.
ChatGPT GPT-5.4 serves 180 million weekly active users the largest active user base among current AI models, according to OpenAI’s 2024 usage data. It integrates natively with Microsoft Office, Zapier, Slack, and HubSpot. This covers the broadest application ecosystem of any current AI model.
Multimodal breadth: GPT-5.4 supports text generation, DALL-E 4 image creation, voice interaction, code generation, and real-time web search within one ChatGPT Plus subscription at $20/month.
Ecosystem integration: ChatGPT connects with 7,000+ applications through Zapier. It supports Microsoft Teams and Office 365 natively. It integrates with HubSpot for marketing automation.
Agentic capability: GPT-5.4 scores 75% on the OSWorld benchmark for autonomous computer interaction. Its Deep Research agent autonomously navigates dozens of web sources for investigative reports. ChatGPT GPT-5.4 scores 75% on OSWorld agentic tasks against Claude Code’s 80.8% SWE-bench score a full head-to-head evaluation is available in the Claude vs ChatGPT comparison. For teams prioritizing deep Microsoft Office 365 integration, a full feature comparison is available in the Copilot vs ChatGPT comparison.
Choose Claude for Long-Context Document Analysis and Enterprise-Safe Outputs
Choose Claude for long-context document analysis and enterprise-safe outputs. Claude Opus 4.6 holds the #1 LMSYS Arena ranking at 1504 Elo. It scores 80.8% on SWE-bench the highest ever recorded, according to Anthropic’s Claude 4.6 technical report, 2026. Anthropic’s Constitutional AI safety framework delivers the highest reasoning accuracy among current flagship models.
Claude 4.6 Max processes 1,000,000 tokens equivalent to approximately 1,500 pages of text. This enables full legal contract review, complete codebase analysis, and multi-document research synthesis within a single session. Anthropic’s Constitutional AI applies structured ethical principles during model training. It produces outputs with lower harmful content rates and higher factual precision on sensitive enterprise tasks including legal analysis, medical documentation, and financial reporting.
Context depth: Claude 4.6 Max processes 1,000,000 tokens in a single context window. This enables analysis of entire legal case files, full software codebases, and complete research datasets without losing track of initial instructions.
Coding leadership: Claude Code achieves 80.8% on SWE-bench Verified. This makes Claude the correct choice for enterprise development teams handling complex architectural refactoring across large multi-file codebases.
Safety framework: Constitutional AI applies structured ethical principles during model training. It produces outputs with lower harmful content rates, higher factual precision, and stronger stylistic consistency. Claude 4.6 scores 80.8% on SWE-bench against Gemini 3.1 Pro’s 63.8% a full reasoning and coding comparison is available in the Claude vs Gemini comparison.
Choose Gemini for Google Workspace Integration and Multimodal Search Tasks
Choose Gemini for Google Workspace integration and multimodal search tasks. Gemini 3.1 Pro scores 94.3% on GPQA Diamond the highest scientific reasoning score among all current flagship models, according to Google DeepMind’s Gemini 3.1 Pro technical report. Native Google Search grounding delivers the strongest research and productivity performance for Google ecosystem users.
Gemini 3.1 Pro holds the #2 position on LMSYS Arena at 1494 Elo. It supports 6 native input modalities text, image, audio, video, code, and documents within a single 1,000,000 token context window. Google AI Pro at $19.99/month bundles Gemini 3.1 Pro with 2TB Google Cloud storage and YouTube Premium.
Scientific reasoning leadership: Gemini 3.1 Pro scores 94.3% on GPQA Diamond. This surpasses GPT-5.4 at 92.0% and Claude Opus 4.6 at 91.3%. It is the correct choice for PhD-level scientific analysis and technical documentation.
Multimodal depth: Gemini 3.1 Pro processes text, image, audio, video, code, and documents natively within 1,000,000 tokens. It enables watching a 45-minute university lecture, analyzing visual diagrams, and summarizing both audio and visual content within a single prompt, according to Google Cloud Vertex AI video understanding documentation.
Google Workspace integration: Gemini 3.1 Pro connects natively with Gmail, Google Docs, Google Sheets, Google Slides, and Google Drive. It enables summarizing a month of emails, formatting a slide deck from a raw spreadsheet, and extracting structured data from Drive documents without requiring Zapier. Gemini 3.1 Pro scores 94.3% on GPQA Diamond against GPT-5.4’s 92.0% a full multimodal and pricing comparison is available in the Gemini vs ChatGPT comparison. For users evaluating Gemini alternatives outside the Google ecosystem, the Grok vs Gemini comparison covers the speed vs reasoning trade-off between Grok 4.20 and Gemini 3.1 Pro.
Choose Perplexity AI for Real-Time Web Research With Source Citations
Choose Perplexity AI for real-time web research with source citations. Perplexity’s source-first RAG architecture performs a fresh web crawl on every query. It delivers inline citations on every response. This eliminates the hallucination risk that non-grounded models including base Claude 4.6 and DeepSeek V3.2 produce on time-sensitive factual queries.
Perplexity AI processes 10 million queries per day making it the dominant AI research tool among journalists, analysts, and fact-checkers, according to Perplexity AI’s 2024 usage data. Perplexity Pro at $20/month provides 300+ Pro searches per day with GPT-5.4 and Claude 4.6 as selectable underlying models.
Source-first architecture: Every Perplexity AI response includes inline citations linking directly to primary web sources. Users verify every factual claim against its origin without secondary research.
Real-time currency: Perplexity AI retrieves live web data on every query. It covers breaking news, recent product releases, current pricing, and real-time market data. Models with fixed knowledge cutoffs DeepSeek V3.2 at July 2024 and Gemini 3.1 at January 2025 cannot access this data without grounding.
Model flexibility: Perplexity Pro subscribers select GPT-5.4 or Claude 4.6 as the underlying reasoning model. This combines real-time retrieval with the 2 highest-ranked LMSYS Arena models within a single $20/month subscription. Perplexity AI’s RAG citation architecture against ChatGPT’s Deep Research agent a full research accuracy comparison is available in the Perplexity vs ChatGPT comparison.
Choose DeepSeek for High-Performance Open-Weight AI at Low API Cost
Choose DeepSeek for high-performance open-weight AI at low API cost. DeepSeek V3.2 costs $0.28 per million input tokens. This is approximately 9x cheaper than GPT-5.4 at $2.50 and approximately 18x cheaper than Claude 4.6 at $5.00. This restructures the economics of high-volume autonomous agent deployment.
DeepSeek V3.2 costs $0.28 per million input tokens approximately 9x cheaper than GPT-5.4. It scores 88.5% on MMLU, within 0.2 percentage points of GPT-5.4’s 88.7%. Developed by High-Flyer Capital in China, DeepSeek V3.2 operates on a Mixture-of-Experts architecture. It activates only 37 billion of 671 billion total parameters per token. DeepSeek V3.2 is an open-weight model developers download, self-host, and deploy it on private infrastructure without third-party API dependency.
Cost leadership: DeepSeek V3.2 at $0.28 per million input tokens delivers the lowest cost-per-intelligent-token ratio among major AI models. Startups deploy thousands of autonomous agents at a monthly cost that GPT-5.4 reaches within a single day of equivalent usage volume.
Open-weight architecture: DeepSeek V3.2’s open-weight design enables full self-hosting on private infrastructure including NVIDIA A100 or H100 clusters for the 671B parameter MoE model. It eliminates third-party API dependency and ensures complete data sovereignty.
Benchmark competitiveness: DeepSeek V3.2 holds the #5 position on LMSYS Arena at 1425 Elo within 59 Elo points of GPT-5.4 at 1484. It delivers a cost-adjusted performance ratio that no US-based proprietary model currently matches. DeepSeek V3.2 scores 88.5% MMLU at $0.28/1M tokens against Gemini 3.1 Pro’s $2.00/1M a full open-weight vs proprietary cost comparison is available in the DeepSeek vs Gemini comparison.
Frequently Asked Questions
Q1: What is the best AI comparison tool in 2026?
The best AI comparison tool in 2026 depends on the evaluation need. Artificial Analysis provides the most objective live benchmark data across 188 models from 50+ providers, according to Artificial Analysis leaderboard data, April 2026. ChatHub enables side-by-side testing across 20+ models simultaneously. Poe provides multi-model access through a single $19.99/month subscription. Ai comparison provides structured comparison content across ChatGPT, Claude, Gemini, Grok, DeepSeek, and Perplexity AI using LMSYS Arena, MMLU, and SWE-bench benchmark data.
Which AI model scores highest on benchmarks in 2026?
Claude Opus 4.6 holds the #1 position on LMSYS Chatbot Arena at 1504 Elo and scores 80.8% on SWE-bench Verified the highest SWE-bench score ever recorded. Gemini 3.1 Pro leads on GPQA Diamond at 94.3% for scientific reasoning. GPT-5.4 leads on HumanEval at 90.2% for Python code generation, according to LMSYS Chatbot Arena leaderboard data, April 2026.
What is the cheapest AI API in 2026?
The cheapest AI API in 2026 is xAI Grok 4.1 Fast at $0.20 per million input tokens. DeepSeek V3.2 follows at $0.28 per million input tokens. Both cost significantly less than OpenAI GPT-5.4 at $2.50 and Anthropic Claude 4.6 at $5.00 per million input tokens, according to provider pricing pages, April 2026.
What is the difference between grounded and non-grounded AI?
Grounded AI models including Perplexity AI, Gemini 3.1 Pro, and ChatGPT with Browse retrieve live web data before generating a response using RAG or native search integration. Non-grounded AI models including base Claude 4.6 and DeepSeek V3.2 generate responses exclusively from static pre-trained weights with a fixed knowledge cutoff date. Grounded models produce lower hallucination rates on current event queries. Non-grounded models produce lower latency and higher creative writing accuracy.
Which AI tool is best for coding in 2026?
Claude Code scores highest for coding tasks with 80.8% on SWE-bench Verified the highest score ever recorded for an AI model resolving real-world GitHub issues, according to Anthropic’s Claude 4.6 technical report, 2026. Cursor follows with a 72% Supermaven code acceptance rate for daily development. GitHub Copilot records a 46% code acceptance rate across 1 million+ active developers, according to GitHub’s Developer Survey 2023.