Mistral 7B vs LLaMA: Best Open-Weight LLM in 2026?

Mistral 7B and LLaMA 3 8B are the 2 most capable open-weight large language models in the 7–8B parameter class. Mistral 7B leads on inference speed, context length, and commercial licensing. LLaMA 3 8B leads on general benchmark scores and instruction-following alignment. 3 primary deployment constraints determine the correct model choice: VRAM availability, context window requirement, and license type.
Both models run locally on consumer hardware. Both publish weights publicly on Hugging Face. Both are free to download and deploy. The architectural decisions separating them Sliding Window Attention, Grouped Query Attention, and training data volume produce measurable differences in inference speed, benchmark performance, and practical use case fit.
What Are Mistral 7B and LLaMA 3, and How Do They Differ?
Mistral 7B and LLaMA 3 8B are open-weight transformer-based large language models trained on publicly available text data, differing in architecture, parameter count, context window, and license.
Mistral 7B is a 7-billion-parameter open-weight language model developed by Mistral AI, a Paris-based AI company founded in 2023. It uses a transformer architecture enhanced with 2 critical architectural innovations: Sliding Window Attention (SWA) and Grouped Query Attention (GQA). Mistral AI releases all Mistral 7B weights under the Apache 2.0 license, permitting unrestricted commercial use.
LLaMA 3 8B is Meta’s 8-billion-parameter open-weight language model, the latest generation of the LLaMA family. Meta trained LLaMA 3 on over 15 trillion tokens of publicly available text 7x more data than LLaMA 2. LLaMA 3 uses a custom Meta license that restricts commercial deployment above 700 million monthly active users.
| Feature | Mistral 7B | LLaMA 3 8B |
| Parameters | 7 billion | 8 billion |
| Context window | 32,768 tokens | 8,192 tokens |
| Architecture | Sparse-attention transformer | Dense transformer |
| Attention type | Sliding Window + GQA | GQA |
| License | Apache 2.0 | Meta custom |
| Minimum VRAM (FP16) | 16GB | 16GB |
| Minimum VRAM (INT4) | ~5GB | ~6GB |
| Training data | Not disclosed | 15 trillion tokens |
The most significant practical difference: Mistral 7B processes 32,768 tokens per prompt 4x more than LLaMA 3 8B’s 8,192-token limit. For tasks involving long documents, legal contracts, or extended codebases, Mistral 7B processes substantially more content per inference call.
What Are the Architecture Differences Between Mistral 7B and LLaMA 3?
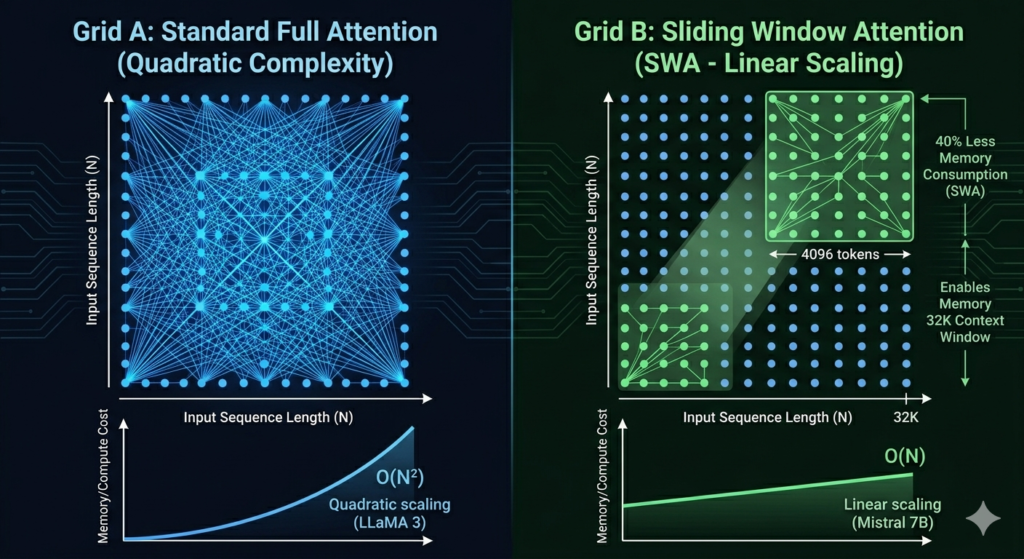
Mistral 7B introduces 2 critical architectural innovations absent from LLaMA 3’s standard dense transformer design: Sliding Window Attention and Grouped Query Attention.
Sliding Window Attention (SWA)
Sliding Window Attention processes each token using only the surrounding 4,096 tokens instead of the full sequence. This reduces memory consumption by approximately 40% compared to full-sequence attention, enabling Mistral 7B to support a 32,768-token context window without proportional VRAM increases. According to Mistral AI’s 2023 technical paper (arXiv:2310.06825), SWA enables linear memory scaling with sequence length rather than quadratic scaling.
Grouped Query Attention (GQA)
Grouped Query Attention groups multiple query heads to share a single key-value head. This reduces inference memory requirements by up to 8x per attention layer compared to Multi-Head Attention, directly increasing tokens-per-second output speed. Both Mistral 7B and LLaMA 3 8B implement GQA, but Mistral 7B combines GQA with SWA LLaMA 3 8B uses GQA with standard full-context attention only.
LLaMA 3 Architecture
LLaMA 3 8B uses a dense transformer architecture with GQA applied across all model sizes and an 8,192-token context window. Meta’s architectural choice prioritizes benchmark performance and instruction-following consistency over inference speed optimization. LLaMA 3 8B scores higher on MMLU (66.6%) than Mistral 7B (60.1%) as a direct result of its larger training dataset 15 trillion tokens vs Mistral 7B’s undisclosed but smaller corpus.
How Does Mistral 7B Perform Against LLaMA 3 on Standard Benchmarks?
Mistral 7B outperforms LLaMA 2 7B across all 5 standard benchmarks MMLU, HellaSwag, WinoGrande, HumanEval, and GSM8K. Against LLaMA 3 8B, LLaMA 3 leads on general knowledge tasks while Mistral 7B maintains speed and efficiency advantages.
Mistral 7B vs LLaMA 2 7B Benchmarks
According to Mistral AI’s technical paper (arXiv:2310.06825), Mistral 7B surpasses LLaMA 2 13B on most benchmark tasks a model nearly 86% larger by parameter count.
| Benchmark | Mistral 7B | LLaMA 2 7B | LLaMA 2 13B |
| MMLU (knowledge) | 60.1% | 45.3% | 54.8% |
| HellaSwag (reasoning) | 81.3% | 77.2% | 80.7% |
| WinoGrande (common sense) | 75.3% | 69.2% | 72.2% |
| HumanEval (coding) | 26.2% | 12.8% | 18.3% |
| GSM8K (math reasoning) | 52.1% | 14.6% | 28.7% |
Mistral 7B vs LLaMA 3 8B Benchmarks
| Benchmark | Mistral 7B | LLaMA 3 8B |
| MMLU | 60.1% | 66.6% |
| HumanEval | 26.2% | 62.2% |
| GSM8K | 52.1% | 79.6% |
| Inference speed (RTX 4090, FP16) | 85–95 tok/sec | 70–80 tok/sec |
| Context window | 32,768 tokens | 8,192 tokens |
LLaMA 3 8B leads on every accuracy benchmark. Mistral 7B leads on inference speed by approximately 15–20% on equivalent hardware. The comparison tightens considerably at the 70B model tier LLaMA 3 70B outperforms Mixtral 8x7B on most benchmarks.
How Fast Is Mistral 7B Inference Compared to LLaMA 3?
Mistral 7B generates 85–95 tokens per second on an NVIDIA RTX 4090 in FP16 precision approximately 15% faster than LLaMA 3 8B’s 70–80 tokens per second on identical hardware.
The speed advantage originates directly from Sliding Window Attention. Processing 1,000 characters of input, Mistral 7B completes inference in approximately 320–380 milliseconds. LLaMA 3 8B completes the same 1,000 characters in approximately 375–430 milliseconds. At scale 10,000 API requests per day this 15% speed difference reduces compute costs proportionally.
INT4 quantized inference speed on RTX 4090:
| Model | INT4 tokens/sec | VRAM required |
| Mistral 7B INT4 | 130–150 tok/sec | ~5GB |
| LLaMA 3 8B INT4 | 110–120 tok/sec | ~6GB |
Deploy Mistral 7B INT4 on hardware with as little as 6GB VRAM, including consumer GPUs such as the RTX 3060, RTX 4060, and RTX 3070.
What Hardware Do Mistral 7B and LLaMA 3 Require?

Mistral 7B and LLaMA 3 8B require identical minimum VRAM in FP16 format 16GB with Mistral 7B requiring 1GB less at INT4 quantization.
Mistral 7B hardware requirements:
- FP16 (full precision): 16GB VRAM RTX 3090, RTX 4080, or equivalent
- INT8 quantized: 10GB VRAM RTX 3080
- INT4 quantized: 5–6GB VRAM RTX 3060, RTX 4060
- CPU inference: 32GB system RAM minimum
LLaMA 3 8B hardware requirements:
- FP16: 16GB VRAM minimum
- INT8: 10–12GB VRAM
- INT4: 6GB VRAM
- CPU inference: 32GB system RAM minimum
Hardware thresholds match at the base model level. Mistral 7B’s architectural efficiency advantage appears in inference speed and throughput not in minimum hardware requirements.
How Does Mistral Instruct Compare to LLaMA 3 Instruct?
Mistral 7B Instruct v0.3 and LLaMA 3 8B Instruct are the 2 chat-optimized variants of their respective base models, differing in training method, context window, and instruction-following consistency.
Mistral 7B Instruct v0.3 is fine-tuned using supervised fine-tuning (SFT) on instruction-following datasets. It supports a 32,768-token context window and is available on Hugging Face at mistralai/Mistral-7B-Instruct-v0.3 under Apache 2.0 license. Mistral Instruct handles multi-step instructions and long-document tasks effectively due to its extended context window.
LLaMA 3 8B Instruct is trained using RLHF (Reinforcement Learning from Human Feedback) and Direct Preference Optimization (DPO). This training approach produces more consistent structured outputs and handles nuanced, multi-constraint instructions with fewer errors than Mistral Instruct. LLaMA 3 8B Instruct scores 79.6% on GSM8K math reasoning 27.5 percentage points higher than Mistral 7B Instruct’s 52.1%.
Choose Mistral 7B Instruct to process long-context documents, legal texts, or RAG pipelines exceeding 8,000 tokens. Choose LLaMA 3 8B Instruct to prioritize instruction accuracy, structured output generation, and math reasoning quality.
How Does Codestral Compare to CodeLlama for Code Generation?
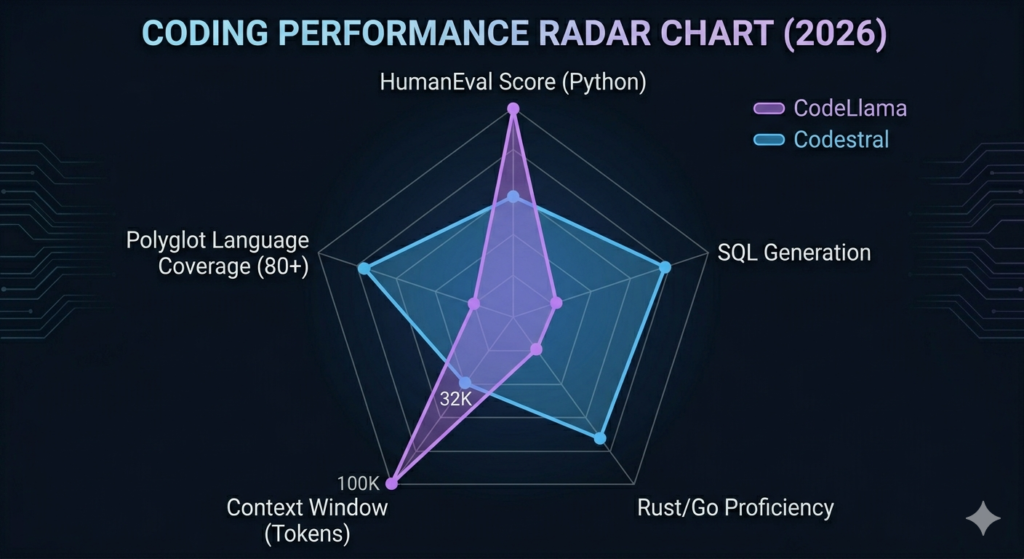
Codestral and CodeLlama are the 2 primary coding-specialized models in the Mistral AI and Meta ecosystems, differing in language coverage, benchmark scores, and context window size.
CodeLlama is Meta’s code generation model built on LLaMA 2. It supports 4 primary programming languages Python, Java, C++, and JavaScript with a 100,000-token context window optimized for large codebases. CodeLlama scores 53.7% on HumanEval, making it the stronger performer on Python-specific coding tasks.
Codestral is Mistral AI’s dedicated code model, released in 2024. It trains on 80+ programming languages, including Rust, Go, SQL, Bash, and TypeScript. Codestral scores 35.34% on HumanEval 18.36 percentage points below CodeLlama but provides broader language coverage across polyglot development environments. The Claude Code vs GitHub Copilot comparison covers additional AI coding tool benchmarks across similar evaluation criteria.
Use CodeLlama on Python-heavy projects requiring high HumanEval accuracy. Use Codestral on polyglot environments requiring consistent support across 80+ languages.
What Is the Difference Between Mistral 7B and Mixtral 8x7B?
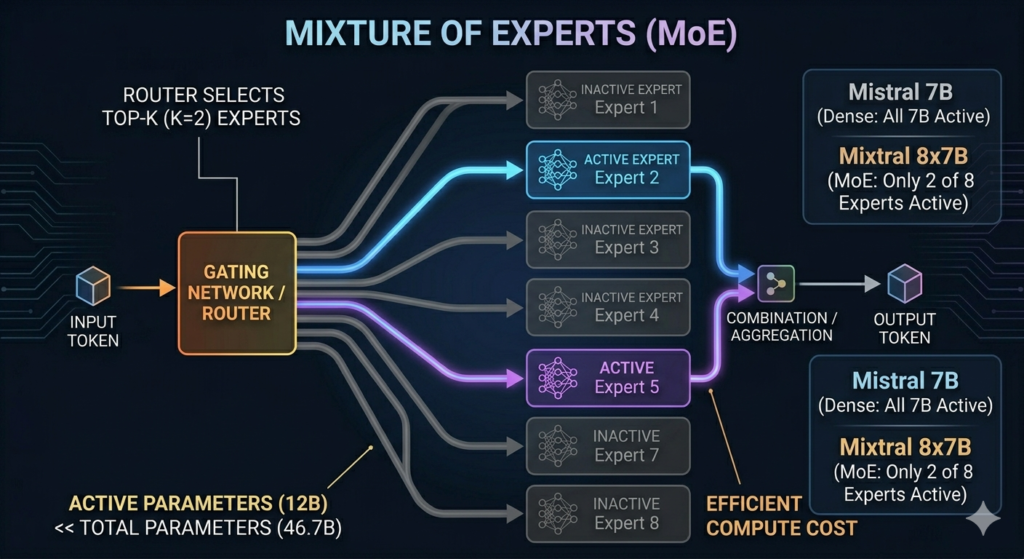
Mistral 7B is a dense 7-billion-parameter model where all parameters activate for every token. Mixtral 8x7B is a Mixture-of-Experts (MoE) model containing 8 expert networks of 7B parameters each 46.7B total parameters where only 2 of 8 experts activate per token during inference.
This MoE architecture gives Mixtral 8x7B the effective compute cost of a 12B dense model while maintaining the knowledge capacity of a 46.7B parameter network. Mixtral 8x7B significantly outperforms Mistral 7B on benchmarks, scoring 70.6% on MMLU compared to Mistral 7B’s 60.1%. However, Mixtral 8x7B requires 48GB VRAM for FP16 inference 3x the hardware requirement of Mistral 7B.
| Model | Parameters | VRAM (FP16) | MMLU | Architecture |
| Mistral 7B | 7B | 16GB | 60.1% | Dense |
| Mixtral 8x7B | 46.7B (active: 12B) | 48GB | 70.6% | MoE |
| LLaMA 3 8B | 8B | 16GB | 66.6% | Dense |
| LLaMA 3 70B | 70B | 140GB | 79.5% | Dense |
How Are Mistral 7B and LLaMA 3 Available on Hugging Face?
Mistral 7B and LLaMA 3 are both available on Hugging Face and downloadable via the transformers library, differing in license terms and model variant naming.
Mistral 7B on Hugging Face 4 primary model variants:
- mistralai/Mistral-7B-v0.1 original base model
- mistralai/Mistral-7B-Instruct-v0.2 second instruct generation
- mistralai/Mistral-7B-Instruct-v0.3 current production instruct variant
- mistralai/Mistral-7B-Instruct-v0.3 release notes confirm function calling support added in v0.3
License: Apache 2.0. No agreement required. Commercial deployment permitted at any scale without user-count restrictions.
LLaMA 3 on Hugging Face 2 primary variants:
- meta-llama/Meta-Llama-3-8B base model
- meta-llama/Meta-Llama-3-8B-Instruct RLHF-aligned instruct variant
License: Meta Llama 3 Community License. Requires accepting Meta’s terms of service. Restricts commercial deployment above 700 million monthly active users.
The licensing difference determines enterprise suitability. Mistral 7B’s Apache 2.0 license permits integration into commercial SaaS products, APIs, and customer-facing applications without legal review. Comparing open-weight models to closed alternatives see the DeepSeek vs ChatGPT analysis for how open models benchmark against proprietary systems.
Is Claude an LLM, and Is Claude Open Source?
Claude is a large language model developed by Anthropic, operating as a closed-weight proprietary system. Anthropic does not release Claude’s model weights publicly. Claude is not open source. The Claude alternatives guide covers open-weight LLMs including Mistral 7B and LLaMA 3 as functional alternatives for developers requiring locally deployable models.
Claude contrasts with both Mistral 7B and LLaMA 3 across 3 primary dimensions: weight accessibility (closed vs open), deployment model (API-only vs local), and licensing (proprietary vs Apache 2.0 / Meta custom). For a direct capability comparison, the Claude vs ChatGPT and DeepSeek vs Claude analyses cover closed-model benchmarks against open-weight competitors.
How Does LLaMA Compare to DeepSeek?
LLaMA 3 and DeepSeek are both open-weight large language models, differing in training approach, benchmark performance, and country of origin. DeepSeek V2, DeepSeek’s most capable open-weight release, uses a MoE architecture with 236B total parameters and 21B active parameters per token outperforming LLaMA 3 70B on several benchmarks at lower inference cost. The full DeepSeek vs ChatGPT comparison covers benchmark data, hardware requirements, and use case differences across both model families. For broader open-weight model context, the DeepSeek alternatives guide includes Mistral 7B, LLaMA 3, and Gemma as evaluated options.
How Does Gemma Compare to LLaMA in the 7B Tier?
Gemma is Google’s open-weight lightweight LLM, available in 2B and 7B parameter sizes. Gemma 7B scores 64.3% on MMLU between Mistral 7B’s 60.1% and LLaMA 3 8B’s 66.6%. Gemma uses Google’s SentencePiece tokenizer and requires acceptance of Google’s custom license for commercial use, similar to Meta’s LLaMA 3 license structure. Gemma 7B requires 16GB VRAM in FP16, matching both Mistral 7B and LLaMA 3 8B hardware requirements.
Which Model Wins: Mistral 7B or LLaMA 3?
Mistral 7B and LLaMA 3 8B serve different primary use cases. Neither model is universally superior across all deployment scenarios.
Choose Mistral 7B to:
- Process long-context documents, legal texts, or research papers exceeding 8,192 tokens
- Deploy commercially without license restrictions or user-count thresholds
- Achieve 15% faster inference speed on equivalent hardware
- Run on minimal hardware 5GB VRAM with INT4 quantization
- Build RAG pipelines requiring 32K+ token context windows
Choose LLaMA 3 8B to:
- Achieve the strongest benchmark scores in the open-weight 7–8B parameter tier
- Prioritize RLHF-aligned outputs with higher instruction-following consistency
- Fine-tune on domain-specific datasets where base model accuracy determines output quality
- Run math-intensive reasoning tasks LLaMA 3 8B scores 79.6% on GSM8K vs Mistral 7B’s 52.1%
Choose Mixtral 8x7B to:
- Access maximum open-weight performance on hardware supporting 48GB VRAM
- Match GPT-3.5 class benchmark performance using open weights
- Process tasks where 70.6% MMLU accuracy justifies 3x the hardware cost of Mistral 7B
For developers building AI comparison tools or evaluating LLMs against proprietary alternatives like GPT-4o, the GPT-4o vs GPT-4.1 benchmark analysis provides the closed-model reference point for positioning Mistral 7B and LLaMA 3 within the broader LLM ecosystem.
Conclusion
Mistral 7B and LLaMA 3 8B differ across 4 measured dimensions: inference speed (Mistral 7B leads by 15%), context window (Mistral 7B: 32,768 tokens vs LLaMA 3 8B: 8,192 tokens), benchmark accuracy (LLaMA 3 8B leads on MMLU by 6.5 percentage points), and license type (Mistral 7B: Apache 2.0 vs LLaMA 3 8B: Meta custom).
Run Mistral 7B Instruct v0.3 from mistralai/Mistral-7B-Instruct-v0.3 on Hugging Face and benchmark it against your specific workload document length, response accuracy, and inference speed on your hardware before selecting a model. Standardized benchmarks such as MMLU, HellaSwag, and HumanEval measure general capability. Performance on your actual production data determines deployment fit.
For teams evaluating the full open-weight LLM landscape, the ChatGPT vs Mistral comparison and LLaMA vs ChatGPT analysis provide direct benchmarks against OpenAI’s GPT model family the primary closed-weight reference point for open-weight model evaluation in 2026.