
DeepSeek vs Claude: Which AI Model Is Better in 2026?
DeepSeek and Claude are 2 large language models representing distinct development philosophies open-source cost efficiency and proprietary safety-first design that dominate AI comparison searches in 2026.This comparison covers 6 critical dimensions coding performance, mathematical reasoning, writing quality, context window, API pricing, and safety compliance to help developers, enterprises, and startups choose the right model for their specific use case.
What Is DeepSeek?
DeepSeek is an open-source large language model family developed by a Chinese AI company founded in 2023 by Liang Wenfeng, co-founder of quantitative hedge fund High-Flyer. DeepSeek builds its model architecture around computational efficiency and open-weights accessibility, activating only 37 billion of its 671 billion total parameters per request through a Mixture-of-Experts (MoE) design.
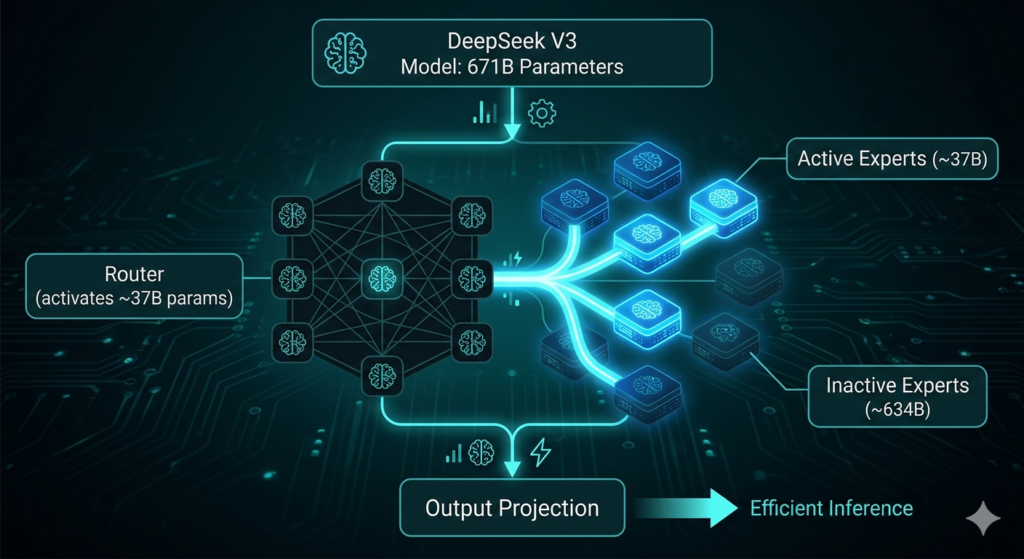
4 core technical innovations define DeepSeek’s architecture in 2026:
- Mixture-of-Experts (MoE): Activates 37B of 671B parameters per request, delivering frontier intelligence at fraction of dense model inference costs
- Multi-head Latent Attention (MLA): Reduces KV cache memory overhead by 93%, maintaining high throughput during long-context operations
- DeepSeek Sparse Attention (DSA): Delivers measurable speed improvements on large documents and extended multi-turn conversations
- Context Caching: Reduces input costs by 90% on repeated prefixes such as static system prompts or large knowledge bases
DeepSeek Models: R1, V3, and Coder V2
DeepSeek offers 3 specialized model families in 2026, each optimized for a distinct class of tasks reasoning, general intelligence, and software engineering. DeepSeek R1 targets complex mathematical reasoning, DeepSeek V3.2 handles general-purpose workloads, and DeepSeek Coder V2 focuses on algorithmic and software engineering tasks.
| Model | Primary Use Case | Key Attribute |
| DeepSeek R1 | Mathematical reasoning | 97.3% on MATH-500 benchmark |
| DeepSeek V3.2 | General intelligence | MoE architecture, 128K–164K context window |
| DeepSeek Coder V2 | Coding and algorithms | 71.6% on Aider Polyglot benchmark |
DeepSeek R2, the dedicated successor to R1, uses large-scale reinforcement learning to develop emergent self-verification capabilities checking its own conclusions without explicit programming. DeepSeek V3.2 introduces the DSA mechanism, delivering speed improvements on tasks involving large documents or extended multi-turn conversations at $0.28 per million input tokens.
DeepSeek Pricing: Free Access and API Cost

DeepSeek provides free chat access through its web and mobile interfaces, with an MIT license that permits self-hosting, fine-tuning, and commercial deployment with no royalty restrictions. DeepSeek’s Context Caching reduces input costs by 90% on repeated prefixes, dropping the effective rate to $0.028 per million tokens a price no proprietary Western model currently matches.
| Model | Input Price (per 1M tokens) | Output Price (per 1M tokens) | Caching Discount |
| DeepSeek V4 Preview | $0.14 | $0.28 | Standard rate |
| DeepSeek V3.2 | $0.28 (cache miss) | $0.42 | $0.028 (90% saving) |
| DeepSeek R2 | $0.55 (cache miss) | $2.19 | ~74% on repeat prefixes |
| DeepSeek R1 | $0.70 | $2.40 | Standard rate |
DeepSeek V3 was trained for approximately $6 million using 2,000 H800 GPUs a fraction of the $100M+ training budgets of Western competitors. This cost structure makes DeepSeek approximately 95% cheaper than Claude Sonnet 4.6 for equivalent token workloads.
What Is Claude?
Claude is a large language model family developed by Anthropic, an AI safety company founded by former OpenAI researchers Dario Amodei and Daniela Amodei in 2021. Anthropic trains Claude using Constitutional AI an 80-page rule-based framework that governs the model’s internal reasoning to reduce sycophancy, bias, and harmful outputs through RLHF methodology.
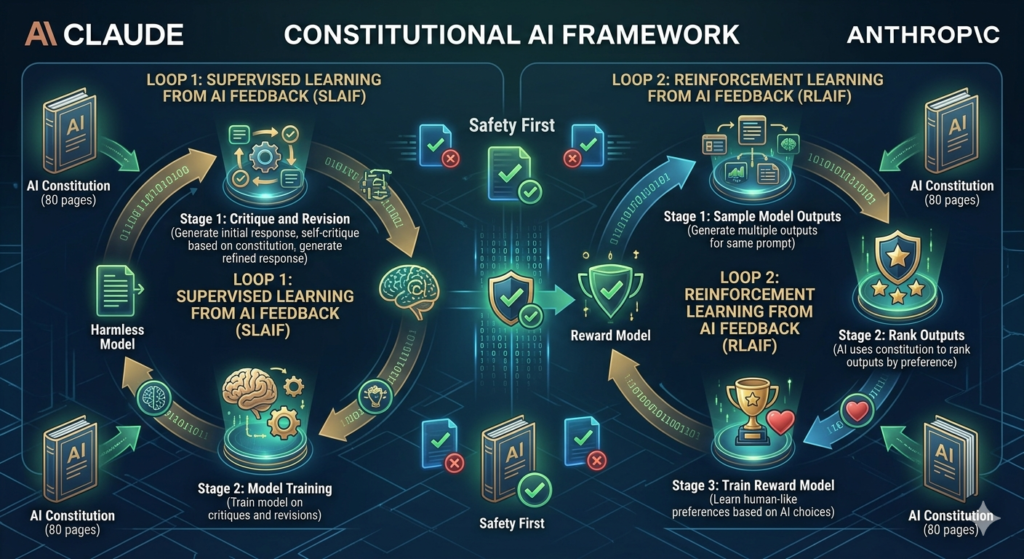
4 core technical capabilities define Claude’s architecture in 2026:
- Constitutional AI training: An 80-page rule framework governs internal reasoning, producing a 99.29% harmless response rate in independent red-team testing
- Hybrid Reasoning: Toggles dynamically between fast execution for routine tasks and Extended Thinking for complex logical challenges
- Extended Thinking mode: Displays visible chain-of-thought reasoning blocks, allowing users to audit each step before the final response
- Agent Teams: Multiple Claude agents divide and execute complex tasks in parallel across large codebases and long-horizon workflows
Claude Models: Sonnet 4.6, Opus 4.7, and Haiku 4.5
Claude’s 2026 lineup consists of 3 primary model tiers, each balancing speed, cost, and intelligence for distinct production requirements. Claude Sonnet 4.6 targets balanced workloads, Claude Opus 4.7 handles peak intelligence tasks, and Claude Haiku 4.5 serves high-volume, cost-sensitive applications.
| Model | Primary Use Case | Key Attribute |
| Claude Opus 4.7 | Complex reasoning and agentic coding | 87.6% on SWE-bench Verified |
| Claude Sonnet 4.6 | Balanced production workloads | 79.6% SWE-bench, $3/M input tokens |
| Claude Sonnet 5 | Next-gen agentic coding | 82.1% on SWE-bench Verified |
| Claude Haiku 4.5 | High-volume, speed-sensitive tasks | $1/M input tokens, 200K context window |
Claude Sonnet 5, released in February 2026, achieves 82.1% on SWE-bench Verified the highest score among all generally available coding models at its launch date. Claude Opus 4.7 introduces Agent Teams, allowing multiple Claude instances to divide and execute complex builds in parallel across long-horizon autonomous workflows.
Claude Pricing: Subscription Plans and API Cost
Claude offers 4 subscription tiers for consumer and enterprise users, with Anthropic’s Batch API providing a 50% discount on non-urgent workloads processed within 24 hours. Prompt caching reduces input costs by up to 90% on repeated context, bringing Claude Sonnet 4.6’s effective input rate to approximately $0.15 per million tokens for RAG systems processing static knowledge bases.
| Plan | Monthly Price | Core Features |
| Free | $0 | Claude Sonnet access with daily usage limits |
| Pro | $20 | All models, Claude Code, 5x usage limits |
| Max 20x | $200 | Highest usage ceiling, priority access |
| Team Premium | $125/seat | Claude Code, administrative tools, collaboration |
For API developers, Anthropic provides tiered pricing across its 3 model families with significant savings available through prompt caching and batch processing.
| API Model | Input ($/1M tokens) | Output ($/1M tokens) | Max Context |
| Claude Opus 4.6/4.7 | $5.00 | $25.00 | 1M tokens |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 1M tokens |
| Claude Haiku 4.5 | $1.00 | $5.00 | 200K tokens |
DeepSeek vs Claude: 6 Key Differences

DeepSeek leads Claude in 3 categories API cost, mathematical reasoning, and open-source flexibility. Claude leads DeepSeek in 4 categories production coding reliability, context window capacity, writing quality, and enterprise safety compliance.
1. Coding Performance
Claude Opus 4.7 achieves 87.6% on SWE-bench Verified the industry’s most rigorous test for autonomous bug-fixing across real open-source GitHub repositories. DeepSeek V3.2 scores approximately 65–70% on equivalent SWE-bench tests, excelling at algorithmic challenges and competitive programming rather than multi-file production builds.
| Benchmark | Claude | DeepSeek | Winner |
| SWE-bench Verified | 87.6% (Opus 4.7) | ~65–70% (V3.2) | Claude |
| Aider Polyglot | Strong | 71.6% (V3.2) | Claude |
| HumanEval | 95.0% (Opus 4.6) | 91%+ (Coder V2) | Claude |
| Code editing error rate | 0% internal | Higher in multi-step | Claude |
Claude handles complex multi-file architecture, traces behavior flow between system components, and resolves real GitHub issues with a 0% internal code-editing error rate. DeepSeek Coder V2 is the stronger choice for isolated function writing, unit test generation, and cost-sensitive automated code review pipelines at up to 50x lower API cost. For a deeper look at Claude’s coding environment, review Claude Code vs Cursor for a direct comparison of the leading agentic development tools in 2026.
2. Mathematical Reasoning
DeepSeek R1 achieves 97.3% on MATH-500 through large-scale reinforcement learning that develops emergent self-verification capabilities. Claude Sonnet 4.6 achieves 97.8% on MATH-500 and Claude Opus 4.6 scores 100% on AIME 2025, leading DeepSeek on structured benchmark tests by 0.5 to 4 percentage points.
| Benchmark | Claude | DeepSeek | Winner |
| MATH-500 | 97.8% (Sonnet 4.6) | 97.3% (R1) | Claude (narrow) |
| AIME 2025 | 100% (Opus 4.6) | 96% (V3.2) | Claude |
| IMO 2025 | Competitive | Gold Medal | DeepSeek |
| GPQA Diamond | 94.2% (Opus 4.7) | 82.4% (V3.2) | Claude |
DeepSeek’s gold medal at IMO 2025 reinforces its position as the premier model for expert-level mathematical competition tasks. Both models have pushed MATH-500 to near-saturation in 2026, making competition-level tests like IMO and AIME the more meaningful differentiators for mathematical reasoning tasks.
3. Writing Quality
Claude produces human-like writing that is emotionally resonant, professionally polished, and requires minimal editing before publication. DeepSeek generates precise, technically structured output that excels at API documentation and engineering specifications but requires more prompt engineering to achieve conversational nuance.
3 writing categories where Claude outperforms DeepSeek:
- Creative writing: Claude mirrors conversational tone and infers user intent without extensive system prompt engineering
- Business communication: Constitutional AI training produces diplomatically balanced, professionally appropriate content across all supported languages
- Multilingual content: Claude supports 60+ languages with high accuracy, including strong performance in South Asian languages such as Hindi, Bengali, and Urdu where DeepSeek shows measurable gaps
A 2026 human preference study found users preferred Claude Opus 4.5 outputs over DeepSeek in 5 out of 7 evaluated behavioral categories, citing helpfulness, diplomatic tone, and natural language quality as the primary differentiators. DeepSeek produces stronger outputs for technical documentation, structured data summaries, and engineering specifications where precision matters more than tone.
4. Context Window
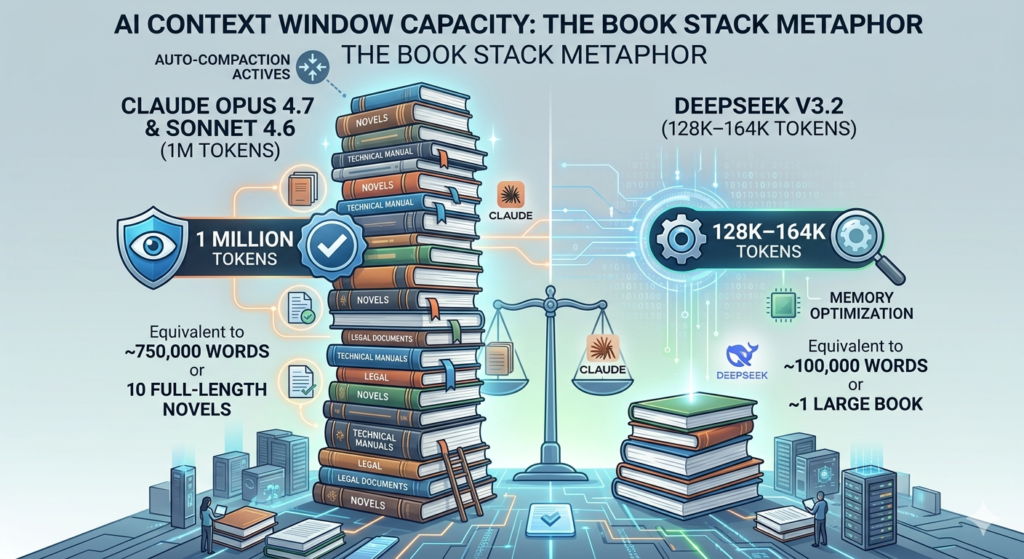
Claude Sonnet 4.6 and Opus 4.7 support up to 1 million tokens via API sufficient to process entire codebases, multi-hour transcripts, or several full-length novels in a single session. DeepSeek V3.2 supports a 128K to 164K token context window, managed through Multi-head Latent Attention (MLA) that reduces KV cache memory overhead by 93%.
| Model | Context Window | Auto-Management Feature |
| Claude Opus 4.7 | 1M tokens (API) | Auto-Compaction at 95% fill |
| Claude Sonnet 4.6 | 1M tokens (API) | Auto-Compaction at 95% fill |
| Claude Haiku 4.5 | 200K tokens | Standard management |
| DeepSeek V3.2 | 128K–164K tokens | MLA memory optimization |
Claude’s Auto-Compaction activates at 95% context fill, automatically summarizing older conversation segments to create effectively infinite context for long-horizon tasks. DeepSeek’s 128K window is sufficient for most focused coding sessions and chatbot applications but falls short for repository-scale analysis or large legal document review exceeding 100,000 words.
5. API Pricing
DeepSeek V3.2 costs $3.50 per 10 million tokens at a 1:1 input/output ratio, compared to $90.00 for Claude Sonnet 4.6 a 96% cost reduction for equivalent high-volume workloads. Claude justifies its premium pricing through superior instruction-following, lower debugging cycles, and higher output reliability in mission-critical production applications.
| Model | Cost per 10M Tokens | Annual Cost (Daily 10M) |
| DeepSeek V3.2 | $3.50 | $1,277 |
| Claude Haiku 4.5 | $30.00 | $10,950 |
| Claude Sonnet 4.6 | $90.00 | $32,850 |
| Claude Opus 4.6 | $150.00 | $54,750 |
DeepSeek is the only viable candidate for high-volume automated pipelines, CI/CD integrations, and customer support agent fleets where cost per interaction dominates the budget. For a comprehensive cost comparison across all major AI models, review DeepSeek vs ChatGPT for full pricing analysis across the 3 leading frontier providers in 2026.
6. Safety and Compliance

Claude achieves a 99.29% harmless response rate in independent red-team testing and maintains industry-leading resistance to prompt injection attacks through Constitutional AI and RLHF training. Claude is available on Amazon Bedrock, Google Vertex AI, and Microsoft Foundry 3 platforms that provide HIPAA and SOC 2 compliance for regulated industries including law, finance, and healthcare.
3 safety dimensions where Claude leads DeepSeek:
- Output safety: 99.29% harmless response rate confirmed in independent red-team evaluations
- Enterprise compliance: HIPAA and SOC 2 standards enforced at the platform level through Amazon Bedrock and Google Vertex AI
- Prompt injection resistance: Constitutional AI training reduces susceptibility to adversarial inputs across all deployment environments
DeepSeek’s self-hosting option ensures sensitive data never leaves the organization’s controlled infrastructure. This makes DeepSeek compliant with GDPR, HIPAA, and SOC 2 requirements for enterprises that cannot route confidential data through third-party APIs a data sovereignty advantage no proprietary cloud-hosted model can replicate.
DeepSeek vs Claude: Benchmark Comparison

Claude leads on production-centric and agentic benchmarks, while DeepSeek demonstrates superior performance on formal logic and open-ended mathematical competition tasks. Both models are evaluated across 3 benchmark categories coding performance, mathematical reasoning, and general knowledge.
| Benchmark | Claude Opus 4.7 | DeepSeek V3.2/R2 | Winner |
| SWE-bench Verified | 87.6% | ~65–70% | Claude |
| GPQA Diamond | 94.2% | 82.4% | Claude |
| MATH-500 | 97.8% (Sonnet 4.6) | 97.3% (R1) | Claude (narrow) |
| AIME 2025 | 100% (Opus 4.6) | 96% | Claude |
| IMO 2025 | Competitive | Gold Medal | DeepSeek |
| HumanEval | 95.0% | 91%+ | Claude |
| MMLU | 91.0% | 88.5% | Claude |
SWE-bench and HumanEval: Coding Benchmarks

SWE-bench Verified measures a model’s ability to autonomously identify and fix bugs across real open-source GitHub repositories Claude Opus 4.7 holds the top position with 87.6%, while DeepSeek V3.2 scores approximately 65–70%. HumanEval measures accuracy on isolated coding functions DeepSeek Coder V2 achieves 91%+, narrowing the gap with Claude significantly on function-level tasks while remaining 50x cheaper per API call.
3 reasons Claude leads DeepSeek on coding benchmarks:
- Multi-file reasoning: Claude traces behavior flow across system components a capability SWE-bench specifically tests and DeepSeek V3.2 scores 17–22 points lower on
- Real GitHub issue resolution: Claude Opus 4.7 resolves actual open-source project bugs with a 0% internal editing error rate
- Agentic execution: Claude Sonnet 5 achieves 82.1% on SWE-bench Verified the highest score at its February 2026 launch date
DeepSeek Coder V2 achieves 91%+ on HumanEval, demonstrating that for focused, algorithmic tasks, DeepSeek is highly competitive with Claude at a fraction of the API cost. For developers choosing between coding-focused AI tools, Claude Code vs Cursor provides a direct comparison of the 2 leading agentic development environments in 2026.
MATH-500 and AIME: Reasoning Benchmarks
MATH-500 evaluates performance on competition-level mathematical problems Claude Sonnet 4.6 scores 97.8% and DeepSeek R1 scores 97.3%, placing both models within 0.5 percentage points on structured math benchmarks. Claude Opus 4.6 scores 100% on AIME 2025, while DeepSeek V3.2 achieves 96% a 4 percentage point gap on the most rigorous structured reasoning test available in 2026.
| Benchmark | Claude | DeepSeek | Gap |
| MATH-500 | 97.8% (Sonnet 4.6) | 97.3% (R1) | 0.5% Claude leads |
| AIME 2025 | 100% (Opus 4.6) | 96% (V3.2) | 4% Claude leads |
| IMO 2025 | Competitive | Gold Medal | DeepSeek leads |
| GPQA Diamond | 94.2% (Opus 4.7) | 82.4% (V3.2) | 11.8% Claude leads |
DeepSeek’s gold medal at IMO 2025 demonstrates that its reinforcement learning-based reasoning produces emergent mathematical capabilities beyond what structured benchmarks measure. Both models have pushed MATH-500 to near-saturation in 2026, making IMO and AIME the more meaningful differentiators for expert-level mathematical reasoning tasks.
MMLU: General Knowledge Benchmark
MMLU evaluates model performance across 57 academic subjects including mathematics, history, law, and medicine with Claude Opus 4.6 scoring 91.0% and DeepSeek V3.2 scoring 88.5%. Claude leads on language-heavy humanities categories and DeepSeek leads on STEM-related knowledge domains, reflecting each model’s distinct training emphasis.
| Model | MMLU Score | Strength Category |
| Claude Opus 4.6 | 91.0% | Humanities, language, professional knowledge |
| Claude Sonnet 4.6 | 89.5% | Balanced across all 57 categories |
| DeepSeek V3.2 | 88.5% | STEM, mathematics, science |
| DeepSeek R1 | 87.1% | Formal logic, technical domains |
Claude’s 2.5 percentage point lead on MMLU reflects Constitutional AI training on diverse, language-rich datasets covering nuanced humanities and professional knowledge areas. DeepSeek’s STEM dominance on MMLU aligns directly with its reinforcement learning focus, making it the stronger general knowledge model for scientific, engineering, and technical research applications.
DeepSeek vs Claude for Coding
Claude leads on production-ready, multi-step agentic builds while DeepSeek excels at algorithmic, cost-sensitive code generation. The choice between DeepSeek Coder V2 and Claude Sonnet 4.6 depends on 3 factors: task complexity, budget constraints, and the level of autonomous execution required.
DeepSeek Coder V2 vs Claude Sonnet 4.6: Code Generation
Claude Sonnet 4.6 produces maintainable, production-ready code with a 0% internal code-editing error rate, making it the stronger choice for day-to-day development in IDEs like Cursor and VS Code. DeepSeek Coder V2 achieves 91%+ on HumanEval and 71.6% on Aider Polyglot, excelling at isolated function writing, unit test generation, and algorithmic problem-solving at 50x lower API cost than Claude.
| Metric | Claude Sonnet 4.6 | DeepSeek Coder V2 |
| SWE-bench Verified | 79.6% | ~65% |
| HumanEval | 95.0% | 91%+ |
| Aider Polyglot | Strong | 71.6% |
| Code editing error rate | 0% internal | Higher in multi-step |
| API cost per 1M input tokens | $3.00 | $0.28 |
| Best for | Production builds | Algorithmic tasks |
Real-world testing confirms Claude Sonnet 4.5 completed a full-stack feature voting application in 50 minutes at $10, while DeepSeek V3.2 completed the same task partially in 1.45 hours at $2. Claude handled ambiguity, ran automated tests after each functionality, and required only 1 manual fix DeepSeek required multiple manual corrections to database and TypeScript configuration files.
DeepSeek R2 vs Claude: Agentic Coding Performance
Claude Opus 4.7 leads all models on agentic coding performance, operating autonomously for 30+ hours to build entire applications, perform security audits, and execute complex multi-step workflows without human intervention. DeepSeek R2 introduces “Thinking in Tool-Use” generating a reasoning path before calling external APIs and self-correcting inconsistent outputs but is positioned as a batch-processing engine rather than a long-horizon autonomous operator.
4 agentic coding capabilities where Claude Opus 4.7 leads DeepSeek R2:
- OSWorld benchmark: Claude Opus 4.6 scores 72.7% on autonomous desktop task execution competitors score 7.8%
- Long-horizon autonomy: Claude operates for 30+ continuous hours on complex builds without human prompting
- Agent Teams: Multiple Claude agents divide and execute tasks in parallel across large codebases
- Error handling: Claude identifies architectural patterns that cause downstream latency and self-corrects proactively before returning output
DeepSeek R2’s “Thinking in Tool-Use” feature advances backend agent frameworks significantly, enabling structured reasoning before each external API call. For developers building cost-efficient background automation agents, DeepSeek R2 delivers strong reasoning depth at a fraction of Claude’s agentic API pricing.
DeepSeek vs Claude for Writing
Claude leads DeepSeek on writing quality across 3 categories creative content, business communication, and multilingual support. A 2026 human preference study confirms Claude leads in 5 of 7 behavioral categories, with users citing tone, nuance, and natural language quality as the primary differentiators over DeepSeek.
Creative Writing: Claude vs DeepSeek Output Quality
Claude produces human-like creative writing that is preferred by users in 5 out of 7 behavioral categories over DeepSeek, requiring minimal editing for polished final drafts. DeepSeek generates structured, technically accurate creative content that requires more precise prompt engineering to achieve the tonal nuance Claude provides in a single generation.
3 creative writing tasks where Claude outperforms DeepSeek:
- Marketing copy: Claude infers brand voice and tone without extensive system prompt engineering, producing conversion-ready content in 1 generation
- Thought leadership content: Claude produces coherent, well-structured long-form articles with natural conversational flow across extended token windows
- Storytelling and narrative: Claude handles emotional resonance, character voice, and conversational drift across documents exceeding 50,000 words
DeepSeek’s creative outputs are precise and factually grounded but tend toward terseness on open-ended prompts. DeepSeek requires additional prompt iterations to match Claude’s first-draft quality for tone-sensitive writing tasks.
Business Writing and Multilingual Support
Claude produces diplomatically balanced business writing across 60+ languages, making it the preferred model for global enterprise teams producing multilingual professional communications. DeepSeek performs strongest in Chinese and English, showing measurable performance gaps in South Asian languages including Hindi, Bengali, and Urdu where Claude’s broader training set provides higher accuracy.
3 business writing scenarios where Claude is the stronger choice:
- Enterprise documentation: Constitutional AI training ensures outputs are diplomatically balanced and professionally appropriate across all 60+ supported languages
- Legal and compliance writing: Claude’s safety-first training produces precise, nuanced language suitable for regulated industries including law, finance, and healthcare
- Global team communications: Claude maintains consistent tone and accuracy across multilingual workflows spanning North America, Europe, and Asia-Pacific markets
DeepSeek’s business writing excels at technical specifications, API documentation, and structured data summaries where precision matters more than tone. For organizations operating primarily in Chinese or English with STEM-heavy content requirements, DeepSeek delivers equivalent writing quality at 95% lower API cost per million tokens.
DeepSeek vs Claude: API Pricing Comparison 2026
DeepSeek API costs up to 96% less than Claude API across equivalent token workloads the largest pricing gap between any 2 frontier AI model providers in 2026. This differential makes DeepSeek the default engine for high-volume automated pipelines and Claude the premium choice for quality-critical production applications.
DeepSeek API Cost vs Claude API Cost Per Million Tokens
DeepSeek V3.2 charges $0.28 per million input tokens and $0.42 per million output tokens, compared to Claude Sonnet 4.6 at $3.00 input and $15.00 output a 10x to 35x pricing gap across standard workloads. DeepSeek’s Context Caching drops input costs to $0.028 per million tokens on repeated prefixes a rate Claude’s proprietary infrastructure cannot match without substantial hardware subsidies.
| Model | Input ($/1M) | Output ($/1M) | Context Caching |
| DeepSeek V4 Preview | $0.14 | $0.28 | Standard rate |
| DeepSeek V3.2 | $0.28 | $0.42 | $0.028 (90% saving) |
| DeepSeek R2 | $0.55 | $2.19 | ~74% on repeat prefixes |
| Claude Haiku 4.5 | $1.00 | $5.00 | 90% saving available |
| Claude Sonnet 4.6 | $3.00 | $15.00 | 90% saving available |
| Claude Opus 4.6/4.7 | $5.00 | $25.00 | 90% saving available |
Claude’s Batch API provides a 50% discount on non-urgent workloads processed within 24 hours. For RAG systems processing static knowledge bases, Claude’s combined caching and batch discounts reduce effective input costs to approximately $0.15 per million tokens still 5x higher than DeepSeek’s cached rate of $0.028.
Enterprise Cost Analysis: 10 Million Token Workload
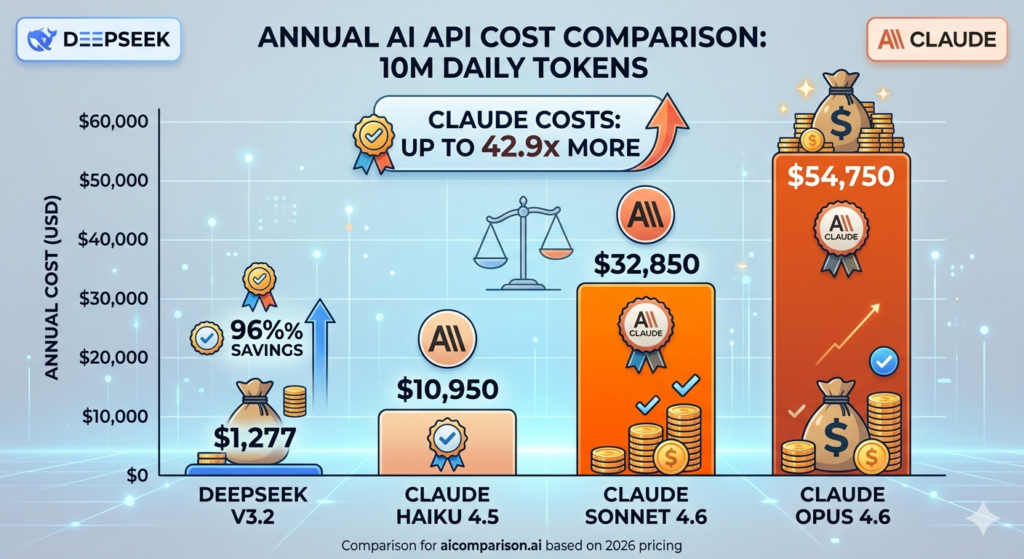
At a daily workload of 10 million tokens 5 million input and 5 million output DeepSeek V3.2 costs $3.50 per day compared to $90.00 for Claude Sonnet 4.6, producing an annual saving of $31,573 for a single enterprise pipeline. Organizations running multiple parallel pipelines including customer support bots, data extraction agents, and CI/CD integrations at this scale save over $100,000 annually by choosing DeepSeek over Claude for bulk processing tasks.
| Provider | Daily Cost | Annual Cost | vs DeepSeek V3.2 |
| DeepSeek V3.2 | $3.50 | $1,277 | Baseline |
| Claude Haiku 4.5 | $30.00 | $10,950 | 8.6x more expensive |
| Claude Sonnet 4.6 | $90.00 | $32,850 | 25.7x more expensive |
| Claude Opus 4.6 | $150.00 | $54,750 | 42.9x more expensive |
Claude’s premium pricing is justified for quality-critical applications where superior instruction-following and higher output reliability directly reduce engineering labor costs. DeepSeek is the only viable option for repository-scale daily analysis, CI/CD pipeline integration, and powering large customer support agent fleets where cost per interaction is the primary budget constraint.
DeepSeek vs Claude: Open-Source vs Proprietary
DeepSeek uses MIT open-source licensing and Claude uses proprietary closed-source deployment 2 models representing opposite ends of the AI accessibility spectrum in 2026. The choice between open-source flexibility and proprietary managed compliance depends on 3 factors: data sovereignty requirements, infrastructure capabilities, and regulatory obligations.
DeepSeek Open-Source Licensing and Self-Hosting Options
DeepSeek’s MIT license grants developers 3 critical freedoms unrestricted fine-tuning on domain-specific datasets, royalty-free commercial deployment, and on-premise self-hosting for 100% data sovereignty. DeepSeek V3 was trained for approximately $6 million using 2,000 H800 GPUs, demonstrating that frontier-level open-source models no longer require the $100M+ training budgets of Western competitors.
3 self-hosting configurations for DeepSeek in 2026:
- Full-scale deployment: 8x H100 80GB GPUs required for the complete 671B parameter DeepSeek V3.2 model
- Quantized INT4 deployment: 4x A100 GPUs sufficient for mid-sized enterprise self-hosting with reduced memory requirements
- Cloud-hosted open-source: Available on Together AI, Hugging Face, and Microsoft Foundry without self-hosting infrastructure requirements
DeepSeek’s self-hosting option ensures sensitive data never leaves the organization’s controlled infrastructure. This makes DeepSeek compliant with GDPR, HIPAA, and SOC 2 requirements for enterprises that cannot route confidential data through third-party APIs.
Claude Enterprise Security and Data Privacy Standards
Claude is available on 3 enterprise cloud platforms Amazon Bedrock, Google Vertex AI, and Microsoft Foundry providing HIPAA and SOC 2 compliance certifications required for production workloads in regulated industries. Claude’s deployment on Amazon Bedrock and Google Vertex AI provides HIPAA and SOC 2 certifications that DeepSeek’s self-hosted open-source deployment cannot guarantee at the platform level.
3 enterprise deployment advantages Claude holds over DeepSeek:
- Managed compliance: HIPAA and SOC 2 standards enforced at the platform level through Amazon Bedrock and Google Vertex AI
- Zero infrastructure management: Developers call the API directly with no hardware optimization or model maintenance required
- Audit-ready reasoning: Claude’s Extended Thinking mode produces visible chain-of-thought reasoning paths for high-stakes decision accountability in law, finance, and healthcare
Claude requires zero infrastructure management developers call the API directly, focusing entirely on the application layer rather than hardware optimization. Organizations evaluating Claude’s full range of safety-focused capabilities benefit from reviewing Claude vs ChatGPT for a broader comparison of the leading proprietary models in 2026.
Is DeepSeek Better Than Claude?
DeepSeek leads in 3 categories API cost, mathematical reasoning, and open-source licensing. Claude leads in 4 categories production coding reliability, context window capacity, writing quality, and enterprise safety compliance. Neither model is universally superior the optimal choice depends entirely on use case, budget, and regulatory requirements.
DeepSeek Advantages Over Claude
DeepSeek holds 3 measurable advantages over Claude across cost efficiency, mathematical reasoning, and open-source flexibility.
3 areas where DeepSeek outperforms Claude:
- API cost efficiency: DeepSeek V3.2 costs $1,277 annually for a 10M daily token workload vs $32,850 for Claude Sonnet 4.6 a 96% cost reduction for equivalent high-volume pipelines
- Open-source licensing: MIT license enables fine-tuning, self-hosting, and commercial deployment with 100% data sovereignty and no royalty restrictions
- Mathematical competition performance: DeepSeek achieved a gold medal at IMO 2025 and scores 97.3% on MATH-500, demonstrating emergent reasoning capabilities that extend beyond structured benchmark performance
DeepSeek’s MoE architecture activates only 37 billion of 671 billion parameters per request, delivering frontier-level intelligence at inference costs that force the entire industry to reduce pricing. For startups, independent developers, and high-volume automation pipelines, DeepSeek’s combination of MIT licensing and 95% lower API cost represents the strongest cost-efficiency advantage among frontier model providers in 2026. Organizations exploring cost-efficient alternatives benefit from reviewing DeepSeek Alternatives for a full map of open-source and budget frontier models available in 2026.
Claude Advantages Over DeepSeek
Claude holds 4 measurable advantages over DeepSeek across production coding, context window, writing quality, and enterprise safety.
4 areas where Claude outperforms DeepSeek:
- Production coding reliability: Claude Opus 4.7 achieves 87.6% on SWE-bench Verified 17–22 percentage points higher than DeepSeek V3.2 on the most rigorous real-world coding benchmark
- Context window capacity: Claude supports 1M tokens via API with Auto-Compaction, compared to DeepSeek’s 128K–164K token limit enabling full codebase and large document analysis in a single session
- Writing quality: Claude produces human-like, emotionally resonant content preferred by users in 5 out of 7 behavioral categories, requiring minimal editing for professional-grade outputs
- Enterprise safety compliance: Claude achieves a 99.29% harmless response rate and maintains HIPAA and SOC 2 compliance through Amazon Bedrock and Google Vertex AI deployments
Claude’s Constitutional AI training and RLHF methodology produce the most reliable instruction-following behavior of any frontier model in 2026, reducing debugging cycles and engineering labor costs for production applications. Organizations evaluating the full proprietary model landscape benefit from reviewing Claude Alternatives for a comprehensive overview of safety-focused models competing with Claude in 2026.
DeepSeek vs Claude: Which AI Should You Choose?
The decision between DeepSeek and Claude in 2026 depends on 4 primary factors budget, task type, compliance requirements, and the level of autonomous execution needed. Many enterprise organizations adopt a hybrid strategy, deploying Claude for high-value strategic reasoning and creative content while using DeepSeek as the cost-efficient engine for bulk technical processing and background automation.
Choose DeepSeek If… / Choose Claude If…
Choose DeepSeek if:
- Cost is your primary constraint: DeepSeek V3.2 costs $1,277 annually for a 10M daily token workload vs $32,850 for Claude Sonnet 4.6 a saving of $31,573 per pipeline
- STEM reasoning dominates your workload: DeepSeek R1 and R2 lead on mathematical competition tasks, engineering calculations, and scientific research where reasoning transparency matters
- Open-source flexibility is required: MIT licensing enables fine-tuning on domain-specific datasets, self-hosting for data sovereignty, and commercial deployment without royalty restrictions
- High-volume automation is your primary build requirement: DeepSeek’s 50x lower API cost makes it the only viable engine for CI/CD pipelines, large customer support agent fleets, and repository-scale daily analysis
Choose Claude if:
- Enterprise compliance is required: Claude’s HIPAA and SOC 2 certifications via Amazon Bedrock and Google Vertex AI are mandatory for law, finance, healthcare, and government applications
- Production coding quality matters: Claude Opus 4.7’s 87.6% SWE-bench score and 0% code-editing error rate deliver the reliability that revenue-critical engineering workflows demand
- Writing quality is essential: Claude produces human-like, professionally polished content across 60+ languages, requiring minimal editing for marketing, legal, and enterprise communications
- Large context window tasks are central: Claude’s 1M token window with Auto-Compaction handles entire codebases, legal datasets, and multi-hour transcripts that exceed DeepSeek’s 128K–164K token limit
For developers comparing coding environments alongside this decision, Claude Code vs Cursor provides a direct comparison of the 2 leading agentic development tools in 2026. Organizations mapping the full AI model landscape before committing to a platform benefit from reviewing DeepSeek vs ChatGPT and Claude vs ChatGPT to understand how both models compare against the most widely used AI assistant in 2026.





